sceneverse.ai
2024 – 2026Data engine for 3D/4D Video-Language Models
Building a data engine for 3D/4D video-language models. The effort produced COM4D (Compositional 4D), accepted at CVPR 2026.
I am a research scientist at INSAIT, previously a senior scientist and postdoc at the Computer Vision Lab in ETH Zurich, in the group of Prof. Luc Van Gool. I completed my PhD thesis under the supervision of Prof. Adrien Bartoli and Prof. Daniel Pizarro in the field of non-rigid 3D reconstruction.
Currently my research scope is diverse, though I have two main focus areas: 3D/4D scene understanding and generation and video understanding.

Data engine for 3D/4D Video-Language Models
Building a data engine for 3D/4D video-language models. The effort produced COM4D (Compositional 4D), accepted at CVPR 2026.
3D Scene & Video Understanding
Industry-academic project on 3D scene and video understanding, applied research and supervision.
Tooth and X-ray image segmentation
Dental image and video segmentation for standard and X-ray imagery — methods and model architecture for an industry partner.
Mapping and tracking for Augmented Reality
Mapping and tracking for AR, covering shape completion, object tracking, and neural radiance fields (NeRF).
3D scans to architectural CAD (IFC)
Generation of architectural CAD (IFC/BIM) models of buildings from 3D scans, based on point-cloud segmentation.
Mobile-cloud 3D scene reconstruction
Mobile-cloud based generic 3D scene reconstruction and applications, including 3D understanding and segmentation.
Microscopic retinal 3D reconstruction
Detection, tracking, and microscopic 3D reconstruction on retinal microscopy images.
Hand-eye calibration and object pose
Hand-eye calibration and object pose estimation for dental augmented reality.

We propose COM4D (Compositional 4D), a method that consistently and jointly predicts the structure and spatio-temporal configuration of 4D/3D objects using only static multi-object or dynamic single object supervision.
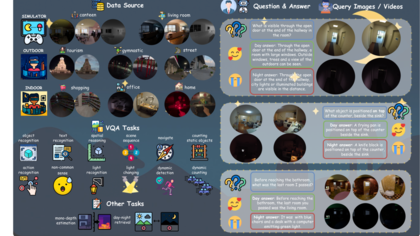
We present EgoNight, the first comprehensive benchmark for nighttime egocentric vision, with visual question answering (VQA) as the core task.

In this work, we address the problem of adapting vision foundation models to new domains in an unsupervised and data-efficient manner, specifically targeting downstream semantic segmentation.

We propose a novel method One2Any that estimates the relative 6-degrees of freedom (DOF) object pose using only a single reference-single query RGB-D image, without prior knowledge of its 3D model, multi-view data, or category constraints.
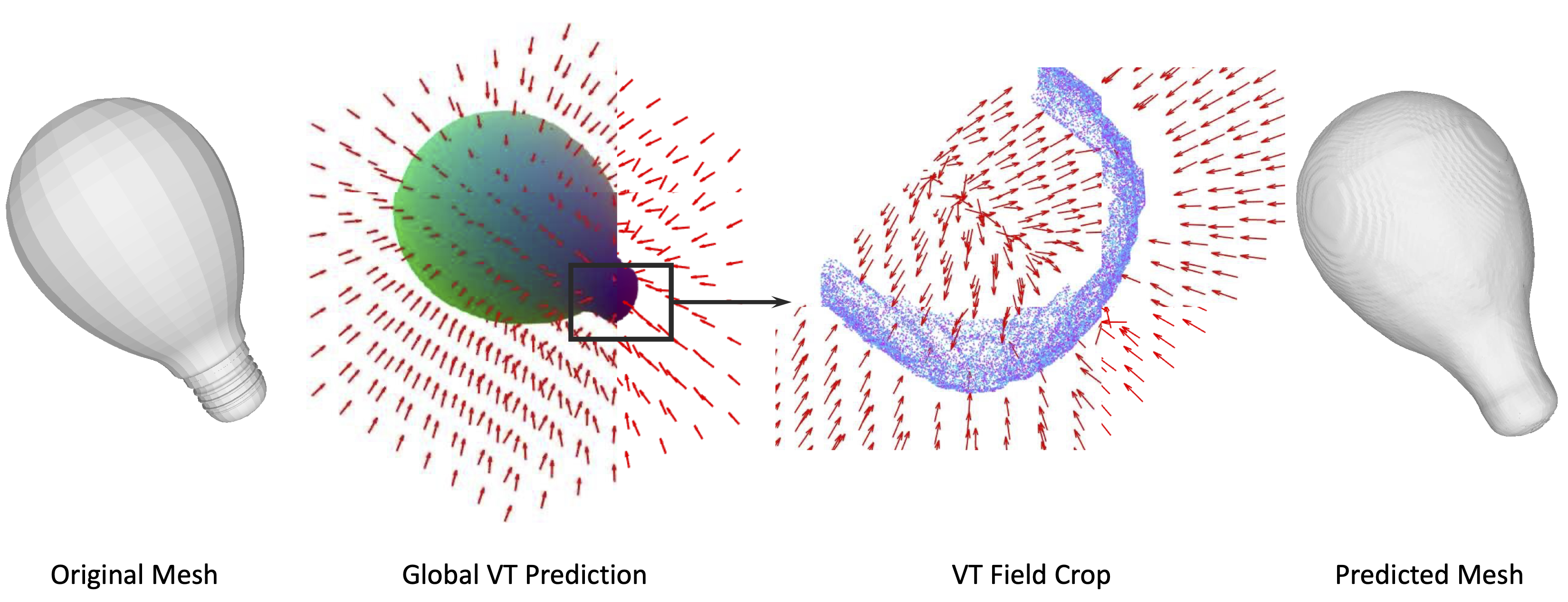
We propose a novel representation for implicit surfaces. This is the first method that can represent open surfaces and also obtain mesh representation with a feedforward network and a Marching Cubes like algorithm.
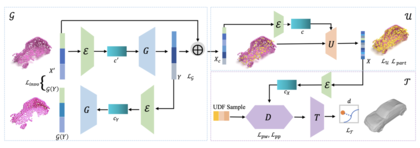
In this paper, we propose a non-adversarial self-supervised approach for the shape completion task.

In this paper, we address indoor dense surface reconstruction by revisiting key aspects of NeRF in order to use the recently proposed Vector Field (VF) as the implicit representation.
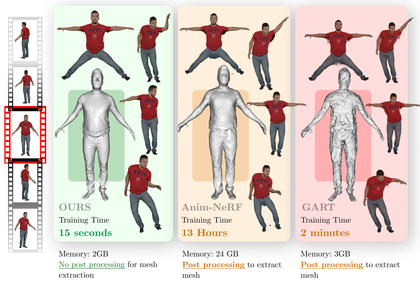
In this paper, we present a fast, simple, yet effective method for creating animatable 3D digital humans from monocular videos.
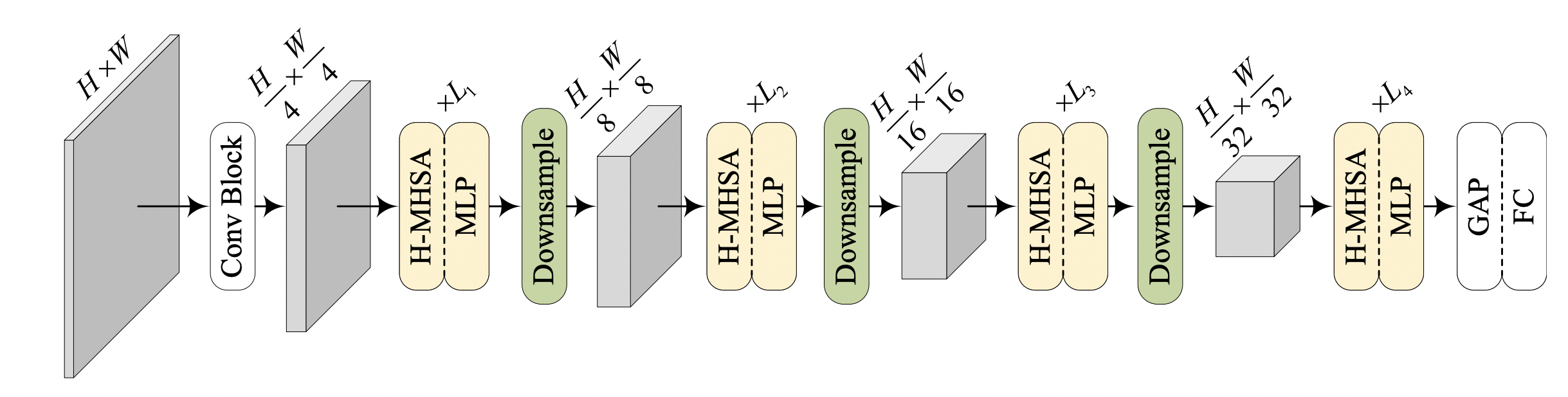
This paper tackles the low-efficiency flaw of the vision transformer caused by the high computational/space complexity in Multi-Head Self-Attention (MHSA). To this end, we propose the Hierarchical MHSA (H-MHSA), whose representation is computed in a hierarchical manner. Specifically, we first divide the input image into patches as commonly done, and each patch is viewed as a token. Then, the proposed H-MHSA learns token relationships within local patches, serving as local relationship modeling. Then, the small patches are merged into larger ones, and H-MHSA models the global dependencies for the small number of the merged tokens. At last, the local and global attentive features are aggregated to obtain features with powerful representation capacity.
Monitoring a fleet of robots requires stable long-term tracking with re-identification, which is yet an unsolved challenge in many scenarios.
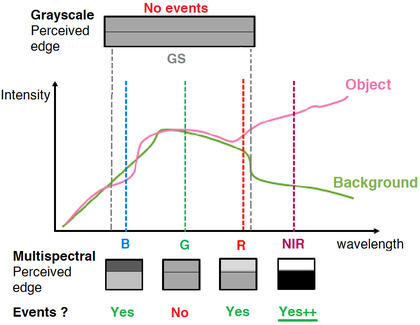
Event-based sensing is a relatively new imaging modality that enables low latency, low power, high temporal resolution and high dynamic range acquisition.

Local image feature descriptors have had a tremendous impact on the development and application of computer vision methods.
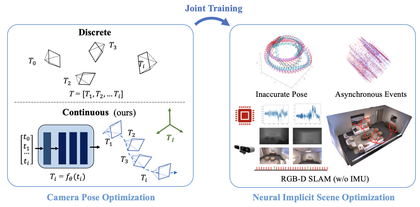
In this paper, we showcase the effectiveness of optimizing monocular camera poses as a continuous function of time.

Modeling Neural Radiance Fields for fast-moving deformable objects from visual data alone is a challenging problem.

Unsupervised template discovery via implicit representation in a category of shapes has recently shown strong performance.
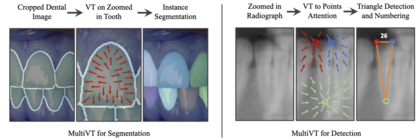
MultiVT introduces a unified transformer-based pipeline that handles detection, segmentation, and landmark localisation on dental radiographs in a single network.
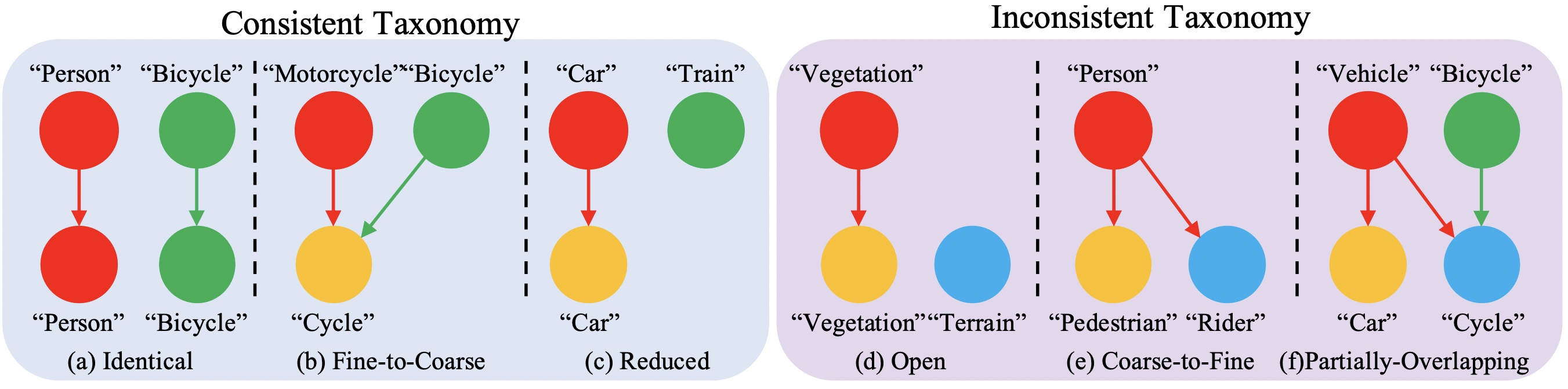
We propose a few shot domain adaptive method for incorporating source and target data which have inconsistent label spaces as well as different input domains. On the label-level, we employ a bilateral mixed sampling strategy to augment the target domain, and a relabelling method to unify and align the label spaces. We address the image-level domain gap by proposing an uncertainty-rectified contrastive learning method, leading to more domain-invariant and class discriminative features.
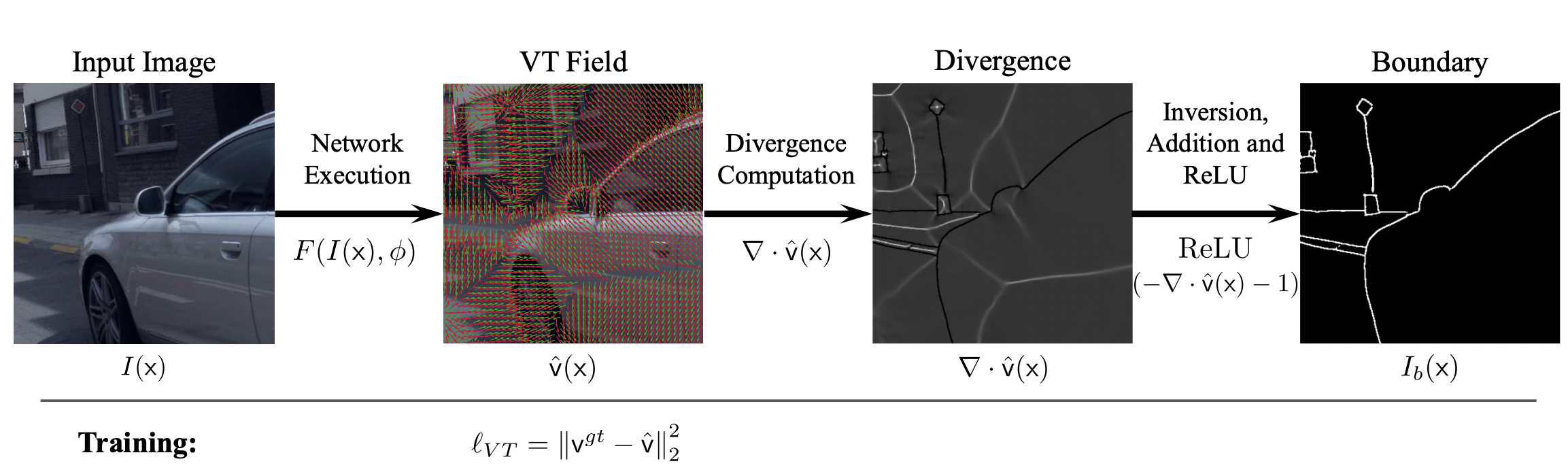
We revisit the boundary detection problem and introduce a principled approach based on a redefinition of boundary with dense labels without label imbalance. We specifically use the unit vector to the closest boundary, beating standard binary label based methods and a baseline method based on distance transform in thorough experiments.
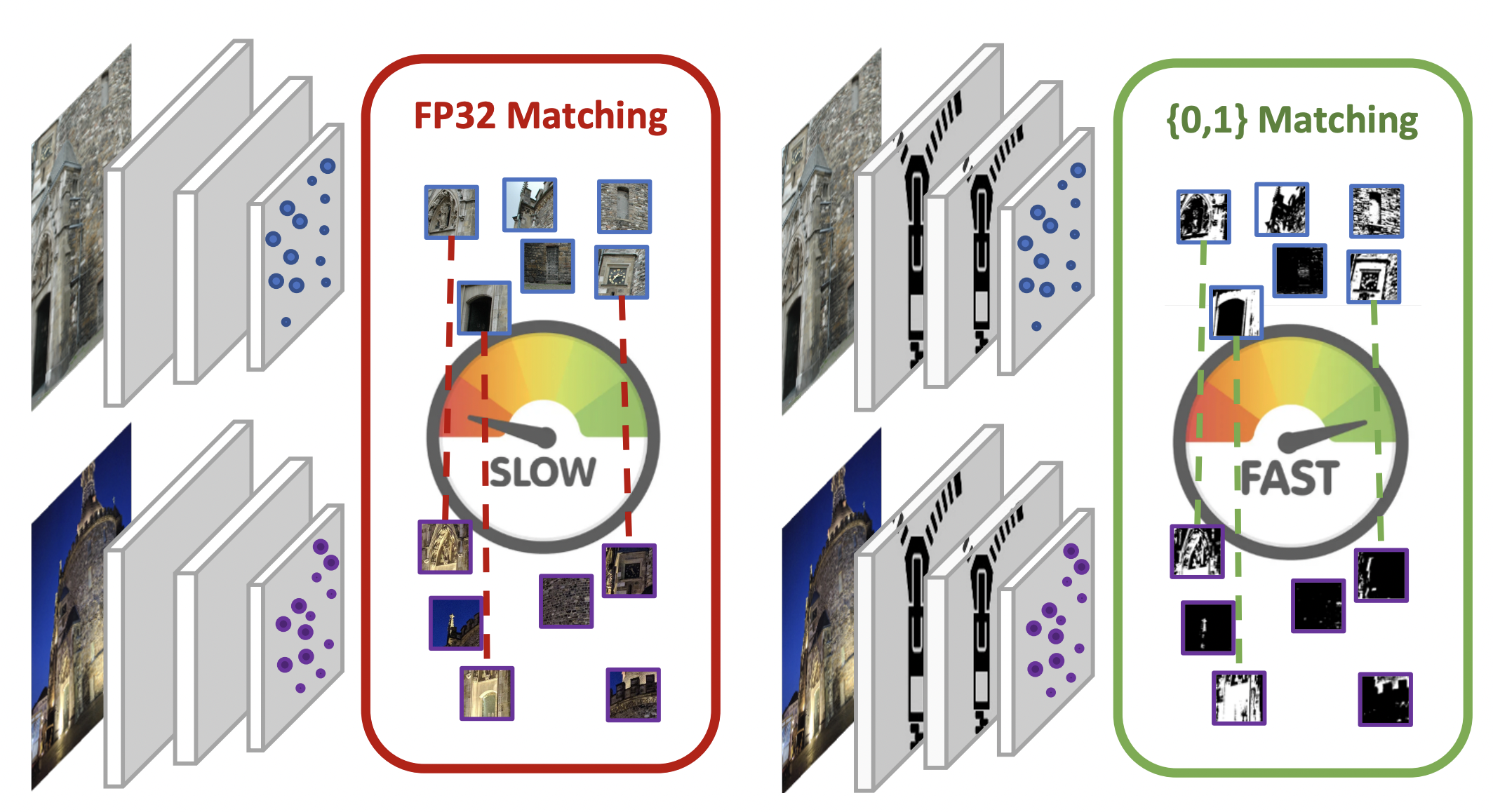
We propose a method for training a fast binary local image point descriptor. The paper describes a method to train binary descriptor by adapting network quantization techniques. The method achieves unprecedented speed in deep local image descriptors.

We present an unsupervised monocular framework for dense depth estimation of dynamic scenes, which jointly reconstructs rigid and nonrigid parts without explicitly modelling the camera motion. Our method uses the as rigid as possible deformation prior.
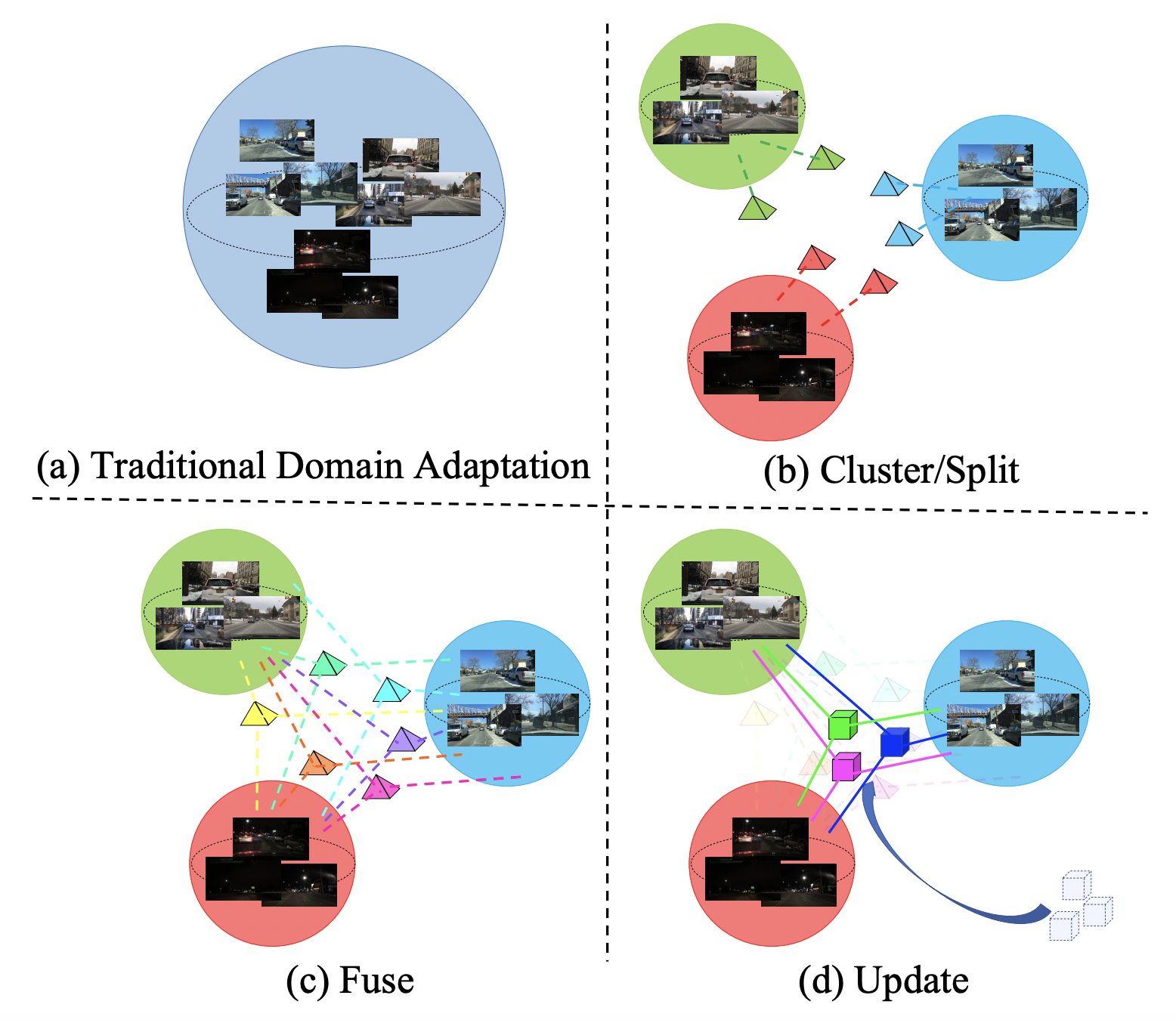
The paper tackles the challenging problem of Open Compound Domain Adaptation (OCDA), where target domain is modeled as a compound of multiple unknown homogeneous domains. We propose a principled meta-learning based approach to OCDA for semantic segmentation, MOCDA, by modeling the unlabeled target domain continuously.
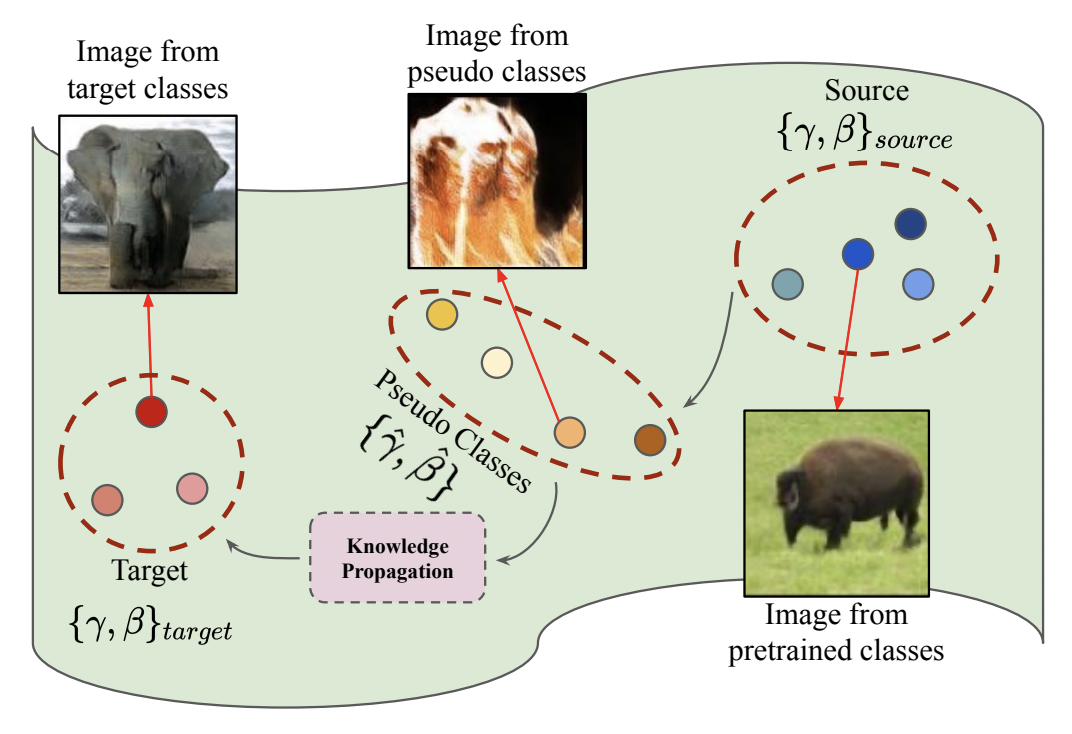
We introduce a new GAN transfer method to explicitly propagate the knowledge from the old classes to the new classes. The key idea is to enforce the popularly used conditional batch normalization (BN) to learn the class-specific information of the new classes from that of the old classes, with implicit knowledge sharing among the new ones. This allows for an efficient knowledge propagation from the old classes to the new ones, with the BN parameters increasing linearly with the number of new classes.
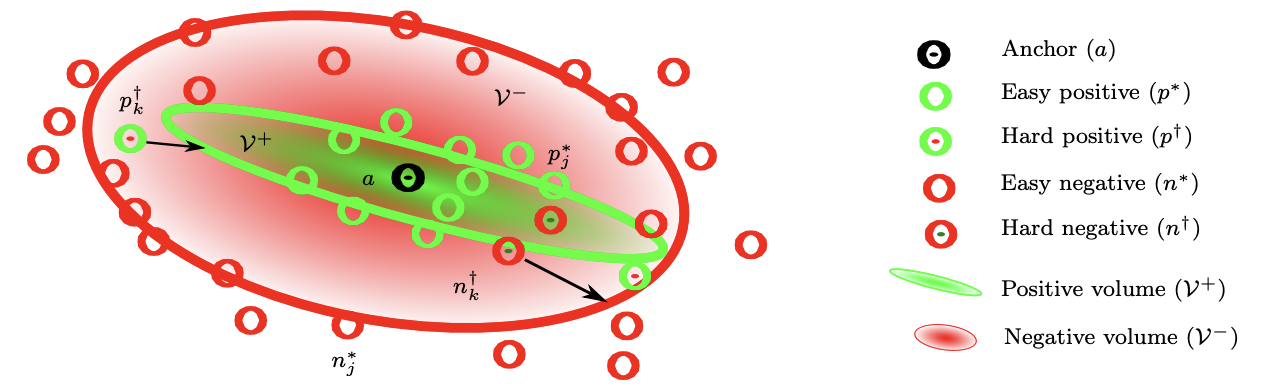
In this paper, we train and evaluate several localization methods on three different benchmark datasets, including Oxford RobotCar with over one million images. This large scale evaluation yields valuable insights into the generalizability and performance of retrieval-based localization. Based on our findings, we develop a novel method for learning more accurate and better generalizing localization features. It consists of two main contributions: (i) a feature volume-based loss function, and (ii) hard positive and pairwise negative mining.
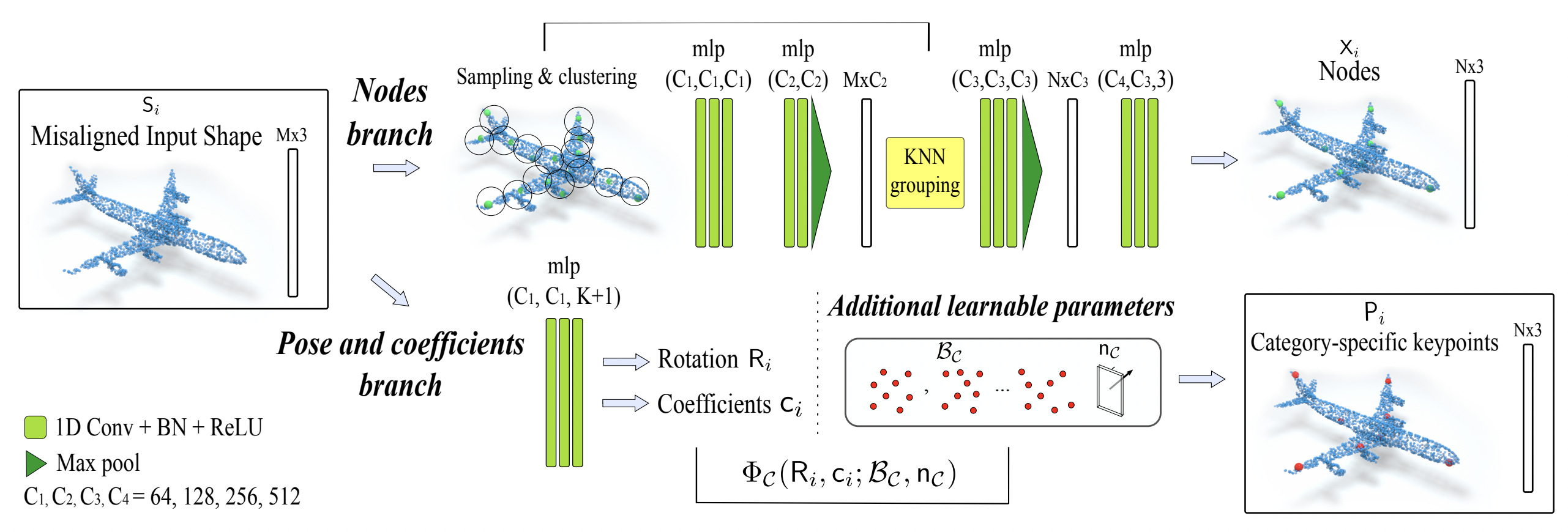
This paper aims at learning semantic 3D keypoints across misaligned shapes in a category, in an unsupervised manner. In order to do so, we model shapes defined by the keypoints, within a category, using the symmetric linear basis shapes without assuming the plane of symmetry to be known. The plane of symmetry and the basis shapes are learned as weights of the network for a category, while the coefficients are predicted per shape instance.
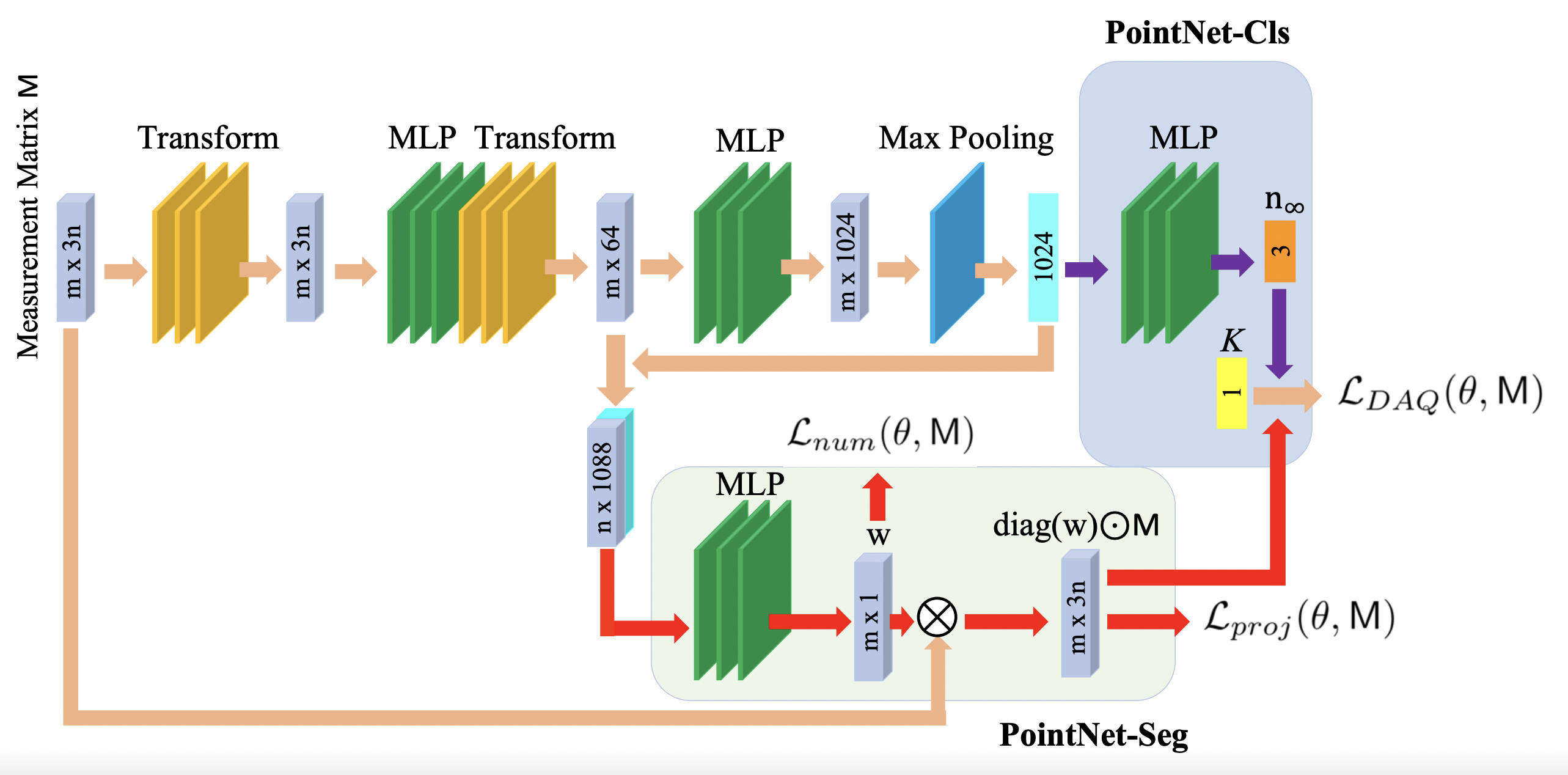
In this paper, we propose a unified SfM method, in which the matching process is supported by self-calibration constraints. We use the idea that good matches should yield a valid calibration. In this process, we make use of the Dual Image of Absolute Quadric projection equations within a multiview correspondence framework, in order to obtain robust matching from a set of putative correspondences.
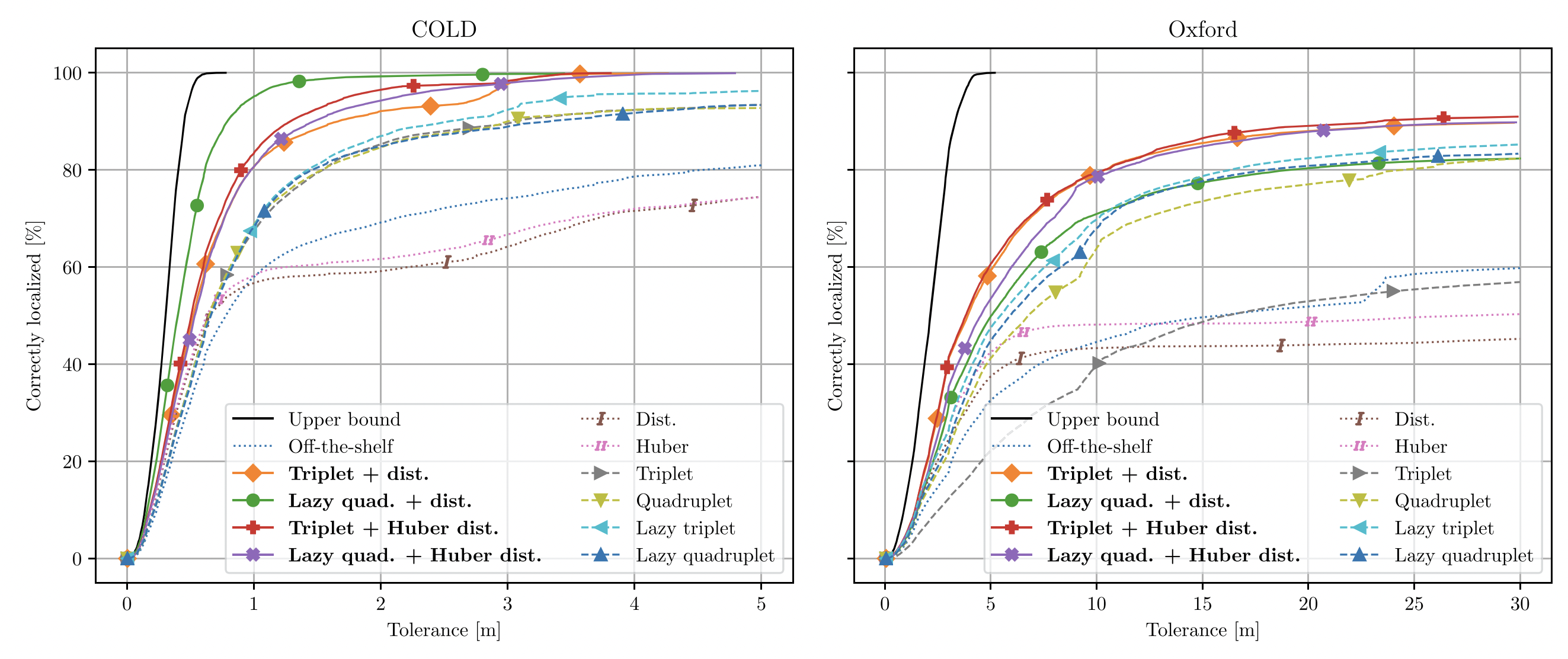
In this work, we propose a method that learns image features targeted for image-retrieval-based localization. Retrieval-based localization has several benefits, such as easy maintenance and quick computation. However, the state-of-the-art features only provide visual similarity scores which do not explicitly reveal the geometric distance between query and retrieved images. Knowing this distance is highly desirable for accurate localization, especially when the reference images are sparsely distributed in the scene. Therefore, we propose a novel loss function for learning image features which are both visually representative and geometrically relatable.

The proposed method exploits the well known Shor’s or Lasserre’s relaxations, whose theoretical aspects are also discussed. Notably, we further exploit the Polynomials Optimization Problems (POP) formulation of non-minimal solver also for the generic consensus maximization problems in 3D vision. We support the proposed framework by three diverse applications in 3D vision, namely rigid body transformation estimation, Non-Rigid Structure-fromMotion (NRSfM), and camera autocalibration
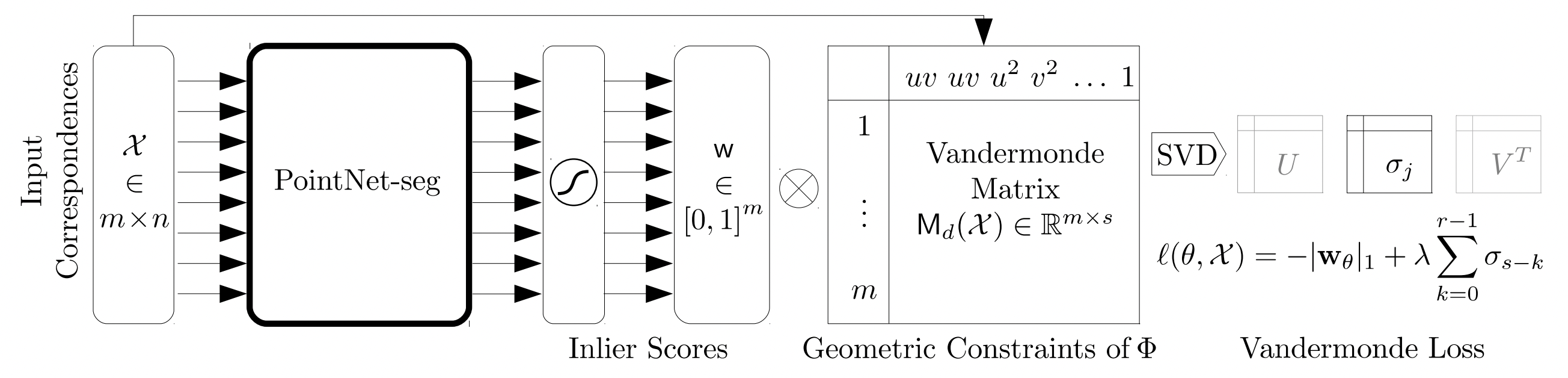
In this paper, we propose for the first time an unsupervised learning framework for consensus maximization, in the context of solving 3D vision problems. For that purpose, we establish a relationship between inlier measurements, represented by an ideal of inlier set, and the subspace of polynomials representing the space of target transformations. Using this relationship, we derive a constraint that must be satisfied by the sought inlier set.
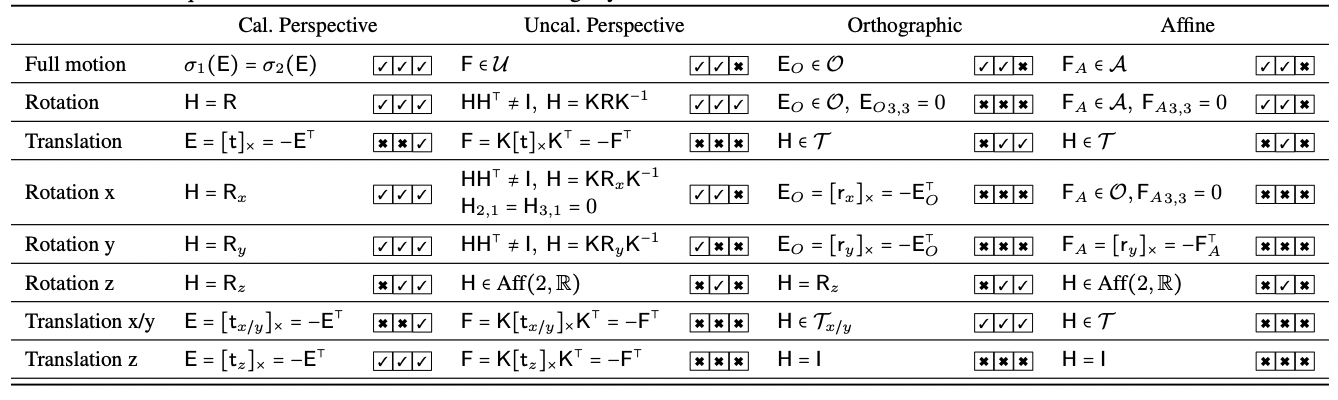
The work describes finding a particular camera geometry from two view image correspondences. We first describe a framework that can be used to compute the `simplest’ camera model for a given set of correspondences. We further provide a theoretical analysis on what type of motions and camera models are discoverable from two view correspondences.
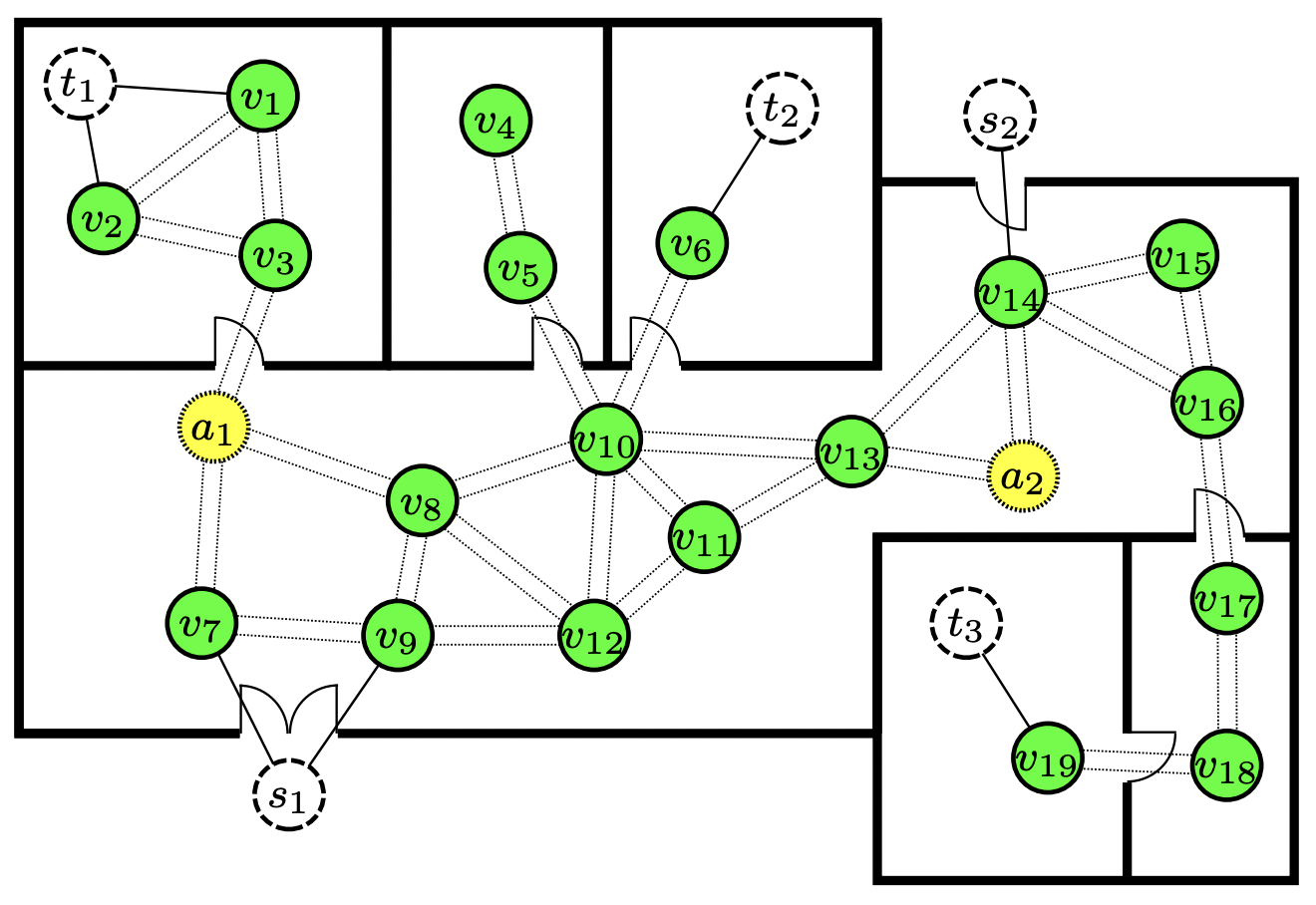
The problem of localization often arises as part of a navigation process. In this paper we summarize the reference images as a set of landmarks, which meet the requirements for image-based navigation. A contribution of this paper is to formulate such a set of requirements for the two sub-tasks involved: compact map construction and accurate self localization. These requirements are then exploited for compact map representation and accurate self-localization, using the framework of a network flow problem. During this process, we formulate the map construction and self-localization problems as convex quadratic and second-order cone programs, respectively.
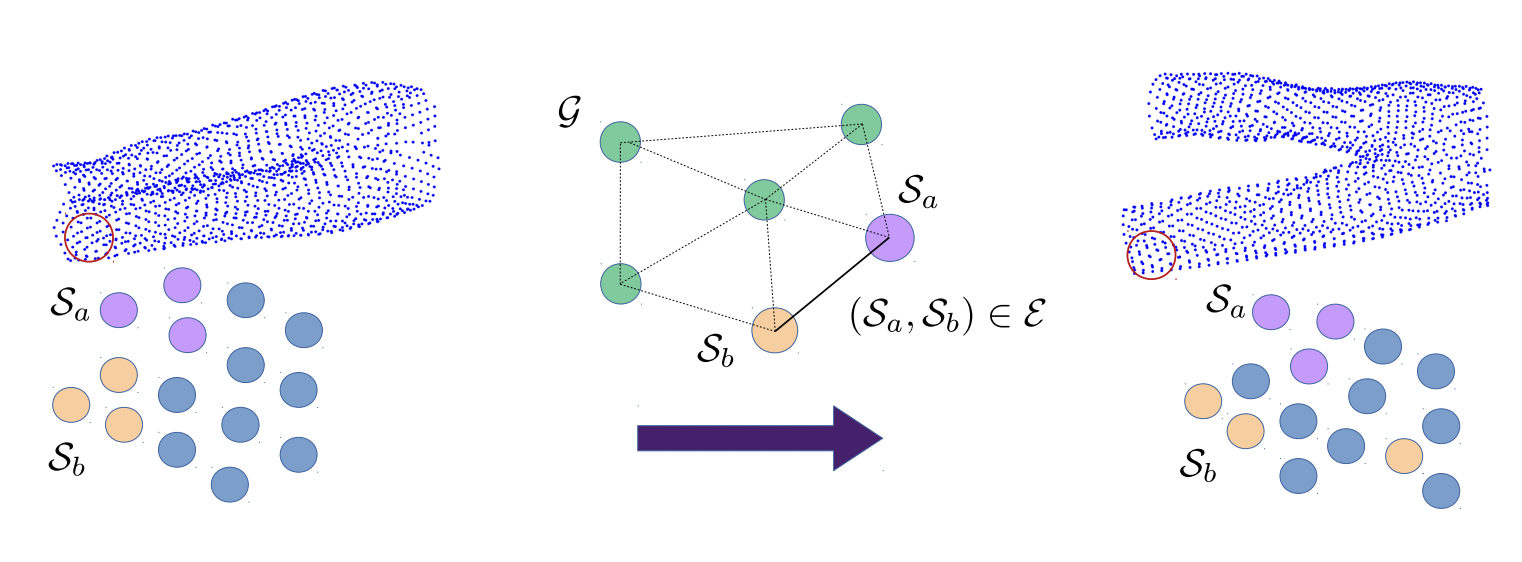
We formulate the model-free consensus maximization as an Integer Program in a graph using ‘rules’ on measurements. We then provide a method to solve it optimally using the Branch and Bound (BnB) paradigm. We focus its application on non-rigid shapes, where we apply the method to remove outlier 3D correspondences and achieve performance superior to the state of the art.

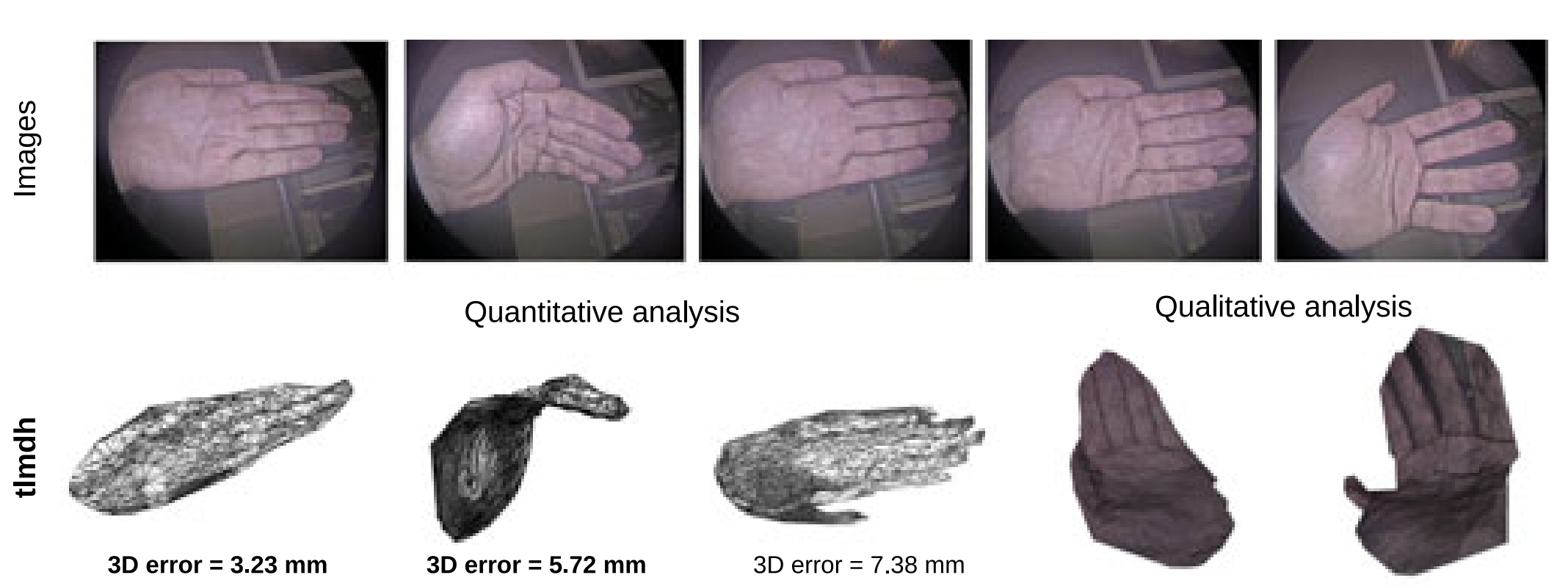
In this paper we present a method for incremental Non-Rigid Structure-from-Motion (NRSfM) with the perspective camera model and the isometric surface prior with unknown focal length. In the template-based case, we provide a method to estimate four parameters of the camera intrinsics. For the template-less scenario of NRSfM, we propose a method to upgrade reconstructions obtained for one focal length to another based on local rigidity and the so-called Maximum Depth Heuristics (MDH). On its basis we propose a method to simultaneously recover the focal length and the non-rigid shapes. We further solve the problem of incorporating a large number of points and adding more views in MDH-based NRSfM and efficiently solve them with Second-Order Cone Programming (SOCP).
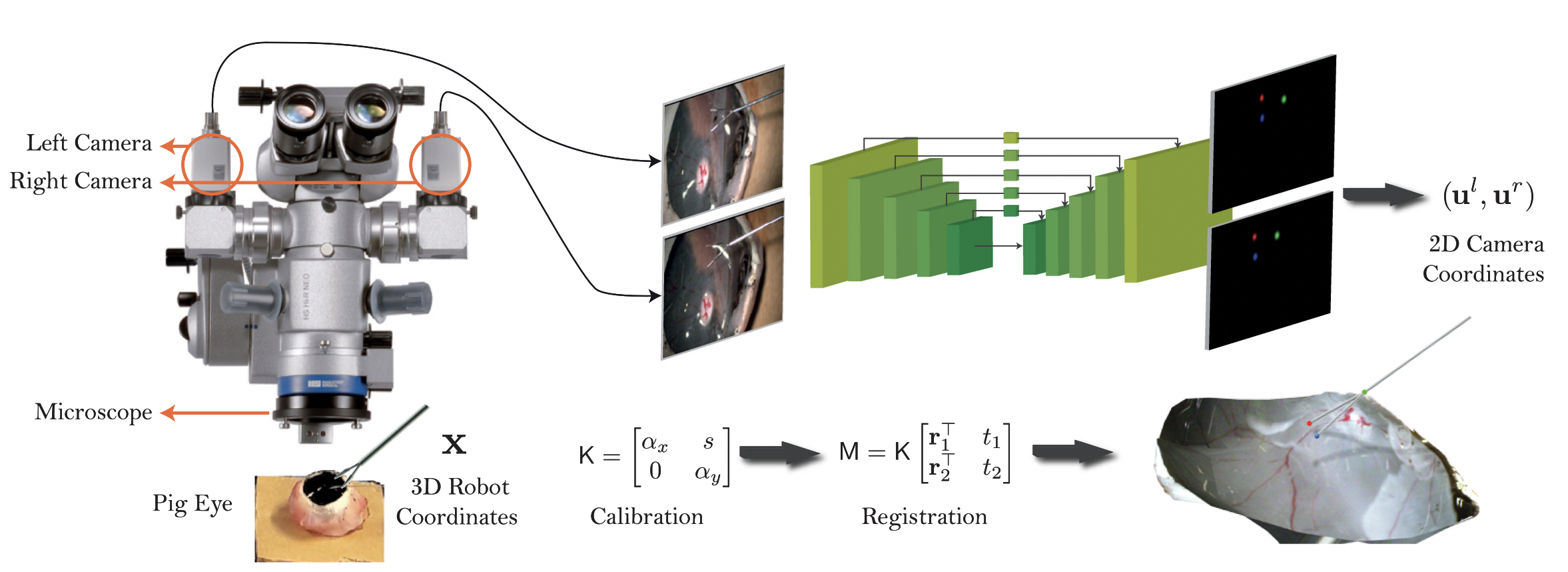
In this paper, we solve the problem of the calibration of stereo-microscope and consequently that of the 3D reconstruction of an unknown scene under the microscope. For the first time using a single pipeline, starting from uncalibrated cameras we achieve the metric 3D reconstruction and registration, for retinal microsurgery. The key ingredients of our method are: (a) surgical tool landmark detection, and (b) 3D reconstruction with the stereo microscope, using the detected landmarks. To address the former, we propose a novel deep learning method that detects and recognizes keypoints in high definition images at higher than real-time speed. We use the detected 2D keypoints along with their corresponding 3D coordinates obtained from the robot sensors to calibrate the stereo microscope using an affine projection model. We design an online 3D reconstruction pipeline that makes use of smoothness constraints and performs robot-to-camera registration.
We present a global and convex formulation for the template-less 3D reconstruction of a deforming object with the perspective camera. We show for the first time how to construct a Second-Order Cone Programming (SOCP) problem for Non-Rigid Structure-from-Motion (NRSfM) using the Maximum-Depth Heuristic (MDH). In this regard, we deviate strongly from the general trend of using affine cameras and factorization-based methods to solve NRSfM, which do not perform well with complex nonlinear deformations. In MDH, the points’ depths are maximized so that the distance between neighbouring points in camera space are upper bounded by the geodesic distance. In NRSfM both geodesic and camera space distances are unknown. We show that, nonetheless, given point correspondences and the camera’s intrinsics the whole problem can be solved with SOCP. This is the first convex formulation for NRSfM with physical constraints. We further present how robustness and temporal continuity can be included in the formulation to handle outliers and decrease the problem size, respectively.
We present a global and convex formulation for template-less 3D reconstruction of a deforming object with the perspective camera. We show for the first time how to construct a Second-Order Cone Programming (SOCP) problem for Non-Rigid Shape-from-Motion (NRSfM) using the Maximum-Depth Heuristic (MDH). In this regard, we deviate strongly from the general trend of using affine cameras and factorization-based methods to solve NRSfM. In MDH, the points’ depths are maximized so that the distance between neighbouring points in camera space are upper bounded by the geodesic distance. In NRSfM both geodesic and camera space distances are unknown. We show that, nonetheless, given point correspondences and the camera’s intrinsics the whole problem is convex and solvable with SOCP.
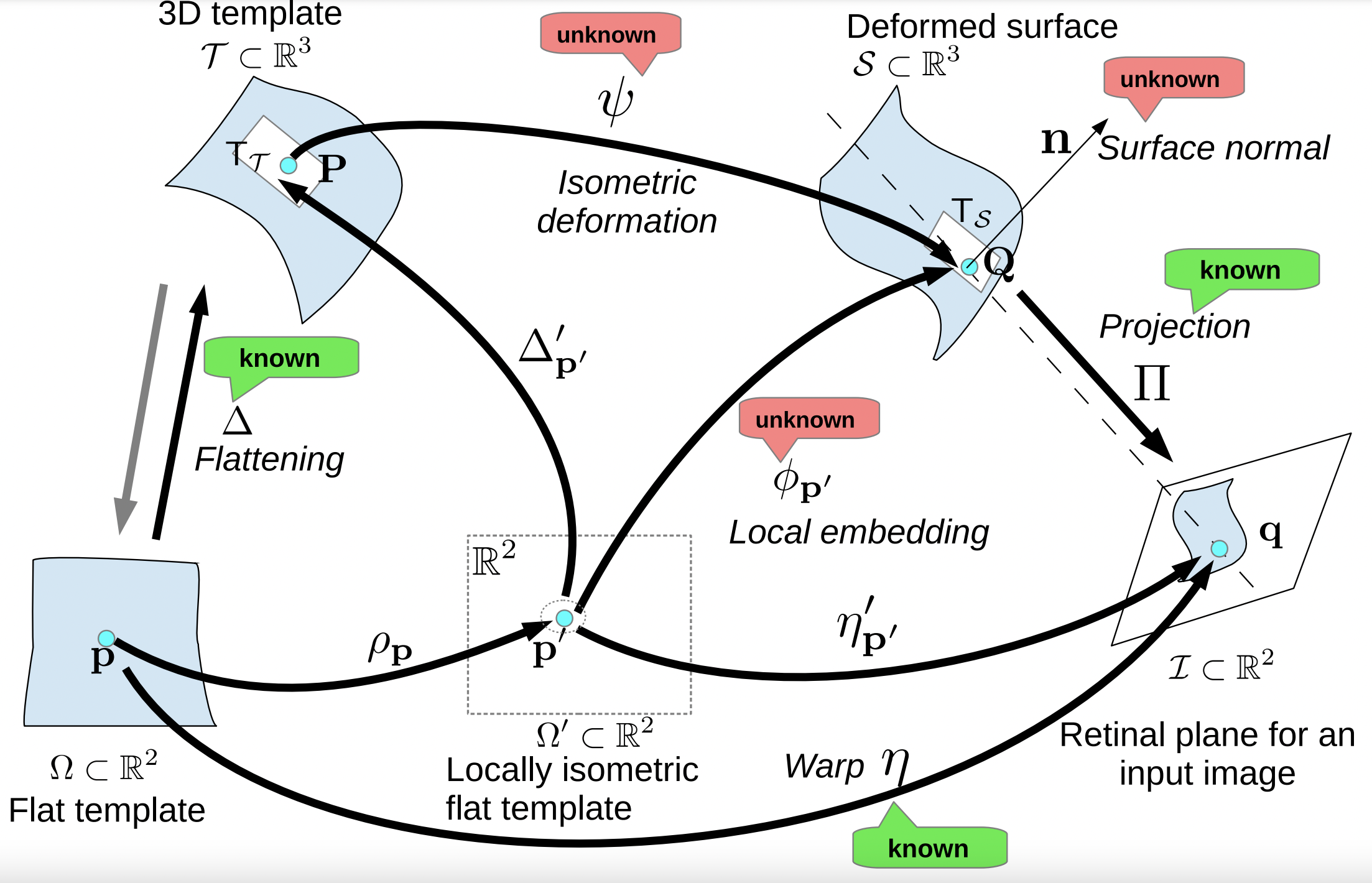
Shape-from-Template (SfT) reconstructs the shape of a deforming surface from a single image, a 3D template and a deformation prior. For isometric deformations, this is a well-posed problem. However, previous methods which require no initialization break down when the perspective effects are small, which happens when the object is small or viewed from larger distances. That is, they do not handle all projection geometries. We propose stable SfT methods that accurately reconstruct the 3D shape for all projection geometries. We follow the existing approach of using first-order differential constraints and obtain local analytical solutions for depth and the first-order quantities: the depth-gradient or the surface normal. Previous methods use the depth solution directly to obtain the 3D shape. We prove that the depth solution is unstable when the projection geometry tends to affine, while the solution for the first-order quantities remain stable for all projection geometries. We therefore propose to solve SfT by first estimating the first-order quantities (either depth-gradient or surface normal) and integrating them to obtain shape.
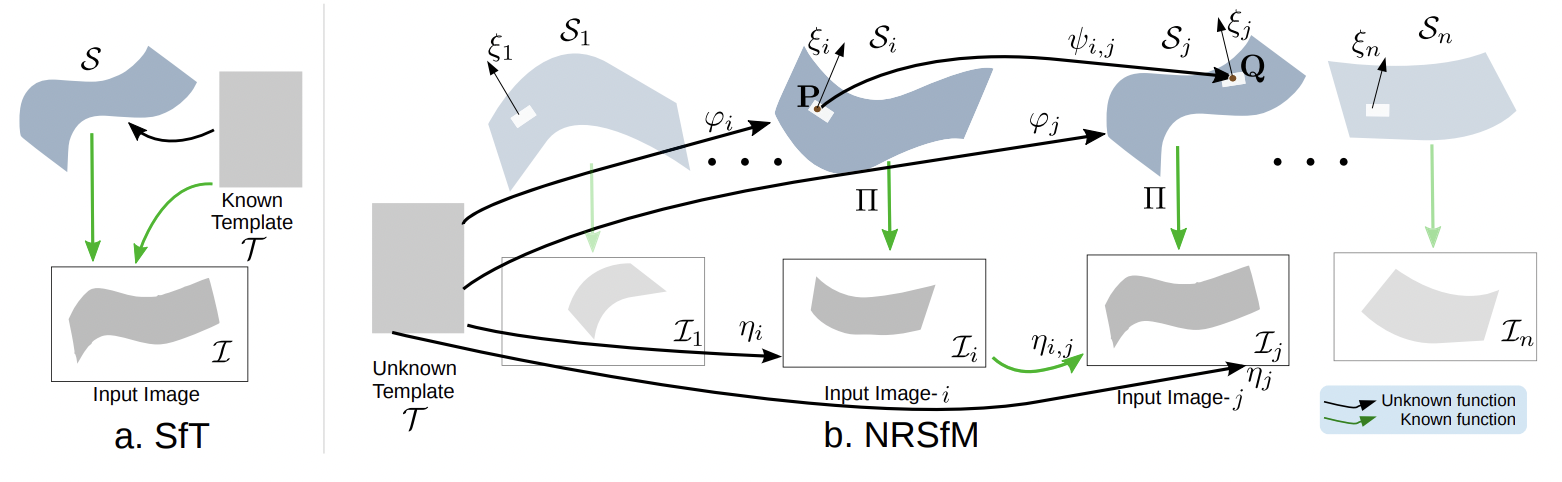
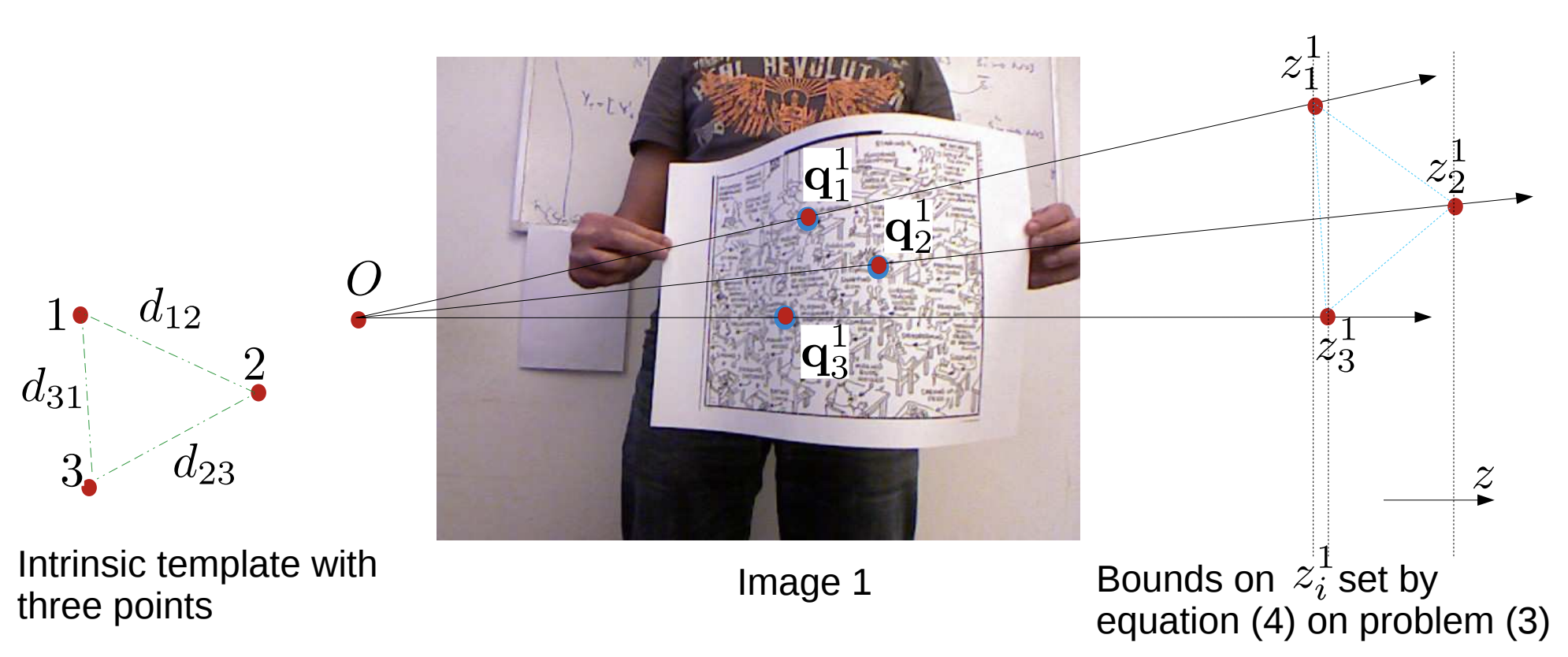
This paper proposes a general framework to solve Non-Rigid Shape-from-Motion (NRSfM) with the perspective camera under isometric deformations. Contrary to the usual low-rank linear shape basis, isometry allows us to recover complex shape deformations from a sparse set of images. Existing methods suffer from ambiguities and may be very expensive to solve. We bring four main contributions. First, we formulate isometric NRSfM as a system of first-order Partial Differential Equations (PDE) involving the shape’s depth and normal field and an unknown template. Second, we show this system cannot be locally resolved. Third, we introduce the concept of infinitesimal planarity and show that it makes the system locally solvable for at least three views. Fourth, we derive an analytic solution which involves convex, linear least-squares optimization only, and outperforms existing works.
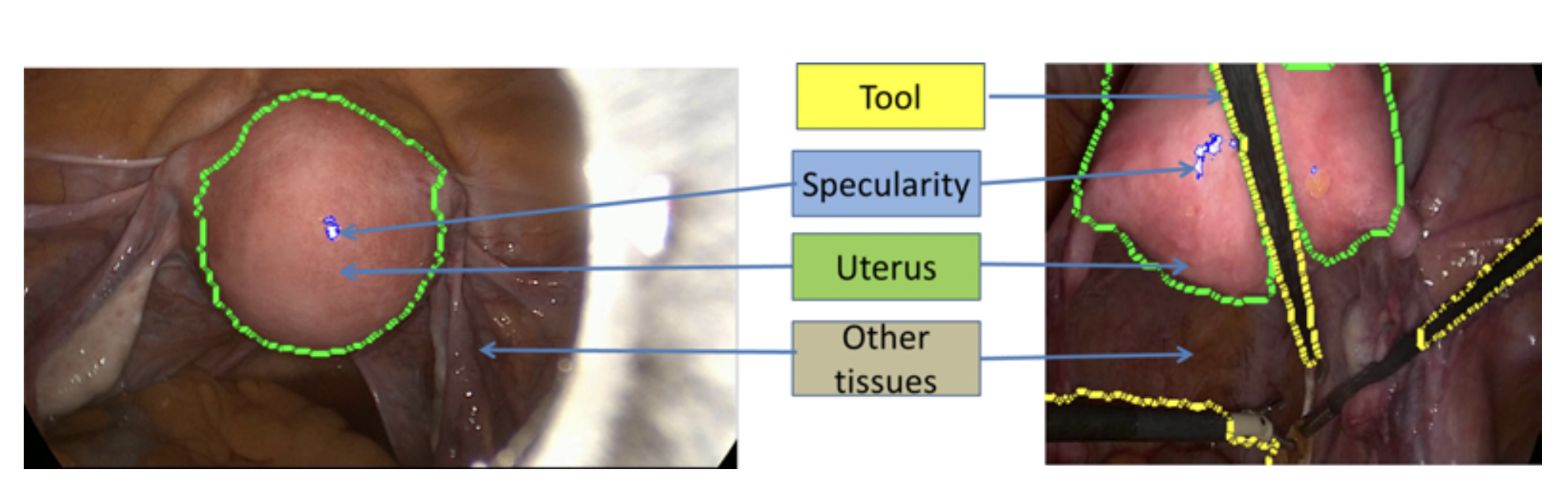
Augmented Reality (AR) can improve the information delivery to surgeons. In laparosurgery, the primary goal of AR is to provide multimodal information overlaid in live laparoscopic videos. For gynecologic laparoscopy, the 3D reconstruction of uterus and its deformable registration to preoperative data form the major problems in AR. Shape-from-Shading (SfS) and inter-frame registration require an accurate identification of the uterus region, the occlusions due to surgical tools, specularities, and other tissues. We propose a cascaded patient-specific real-time segmentation method to identify these four important regions. We use a color based Gaussian Mixture Model (GMM) to segment the tools and a more elaborate color and texture model to segment the uterus. The specularities are obtained by a saturation test. We show that our segmentation improves SfS and inter-frame registration of the uterus.
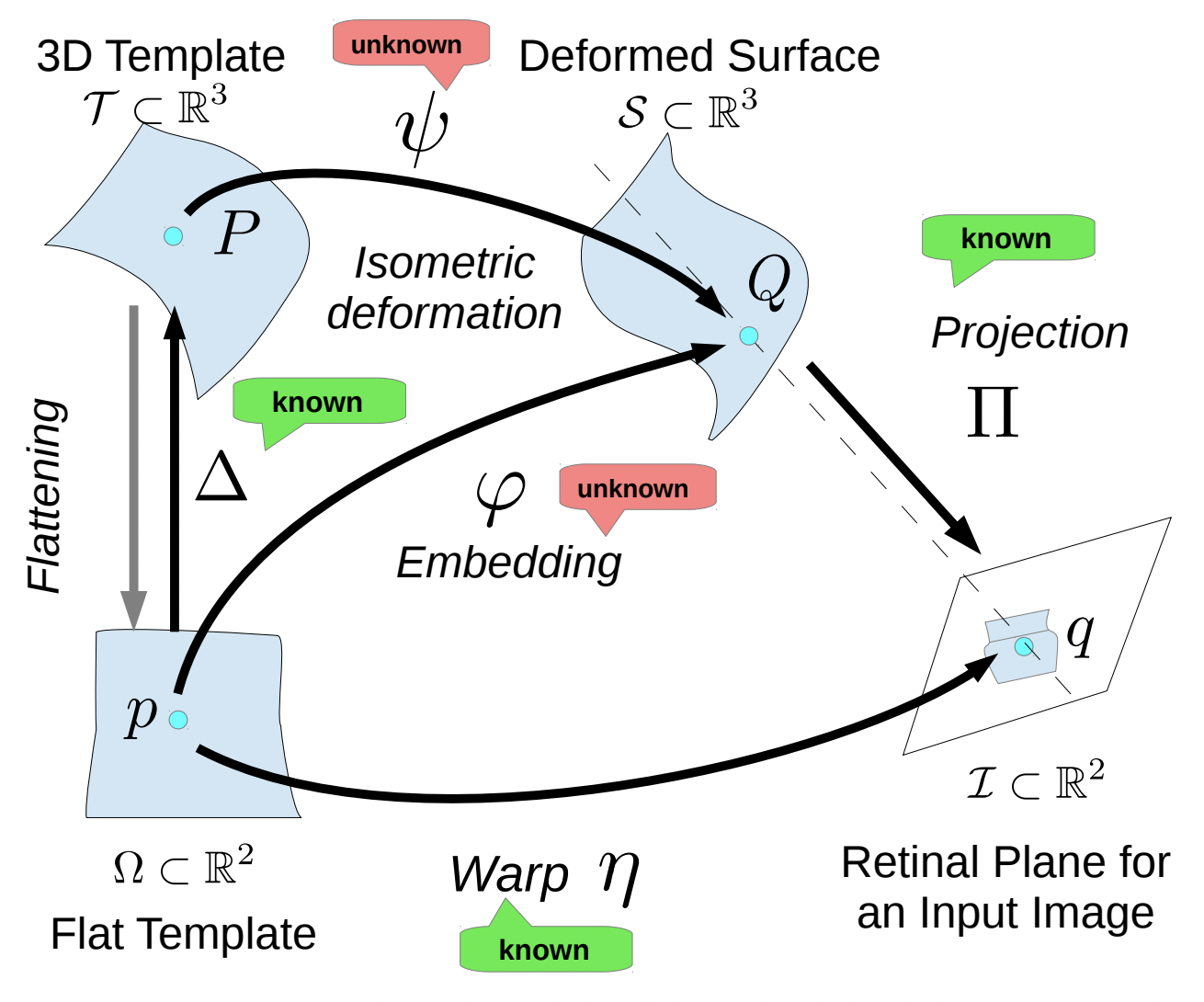
Reconstructing an isometric surface from a single 2D input image matched to a 3D template has been shown to be a well-posed problem. This however does not tell us how reconstruction algorithms will behave in practical conditions, where the amount of perspective is generally small and the projection thus behaves like weak-perspective or orthography. We here bring answers to what is theoretically recoverable in such imaging conditions, and explain why existing convex numerical solutions and analytical solutions to 3D reconstruction may be unstable. We then propose a new algorithm which works under all imaging conditions, from strong to loose perspective by using the algebraic solution of the depth’s Jacobian.

Journal images represent an important part of the knowledge stored in the medical literature. Figure classification has received much attention as the information of the image types can be used in a variety of contexts to focus image search and filter out unwanted information or ”noise”, for example non–clinical images. A major problem in figure classification is the fact that many figures in the biomedical literature are compound figures and do often contain more than a single figure type. Some journals do separate compound figures into several parts but many do not, thus requiring currently manual separation. In this work, a technique of compound figure separation is proposed and implemented based on systematic detection and analysis of uniform space gaps. The method discussed in this article is evaluated on a dataset of journal figures of the open access literature that was created for the ImageCLEF 2012 benchmark and contains about 3000 compound figures. Automatic tools can easily reach a relatively high accuracy in separating compound figures. To further increase accuracy efforts are needed to improve the detection process as well as to avoid over–separation with powerful analysis strategies.