Inferring Compositional 4D Scenes without Ever Seeing One
Short description
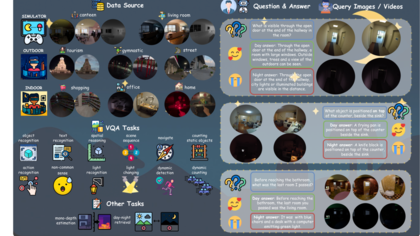
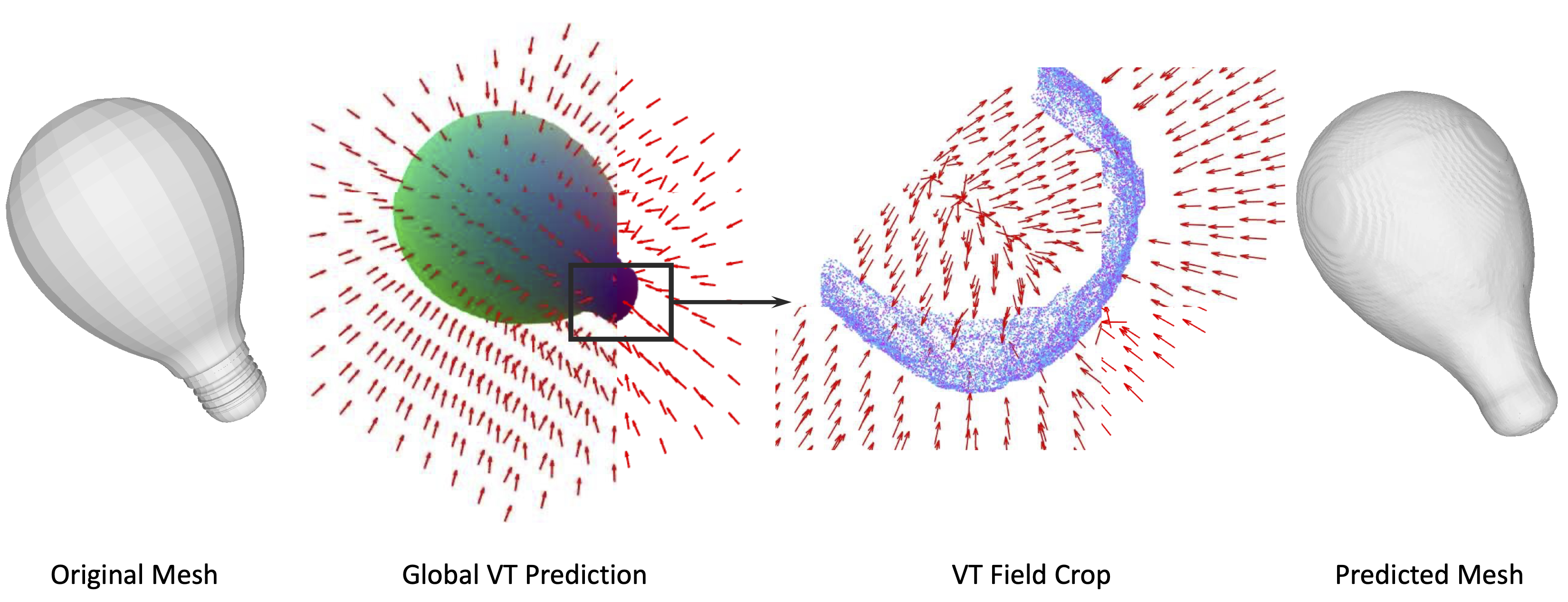
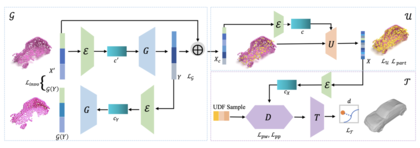
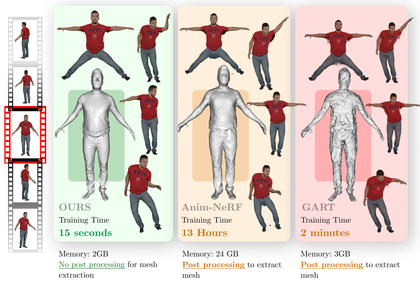
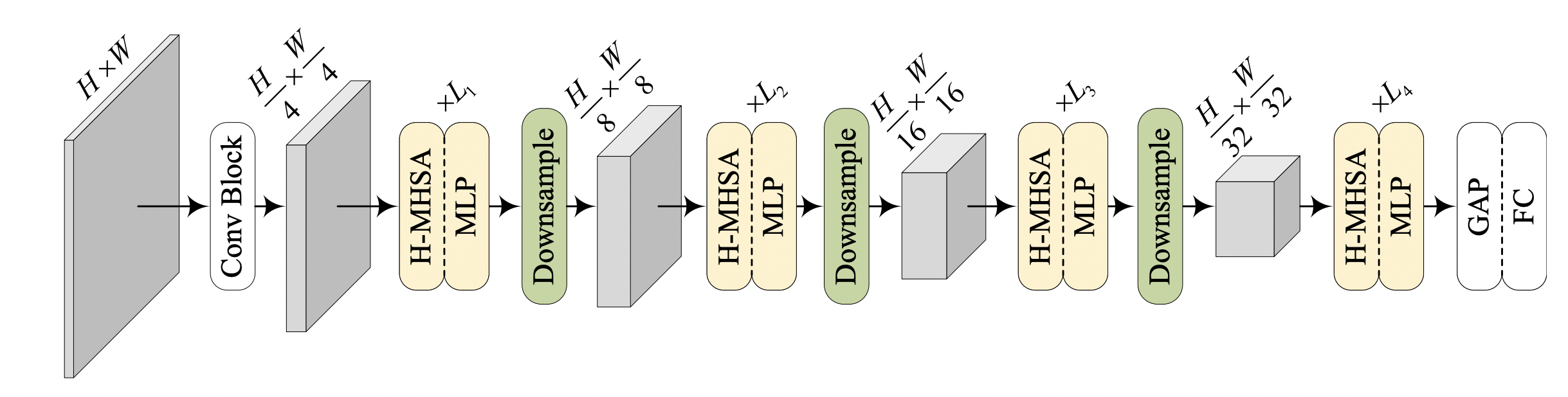
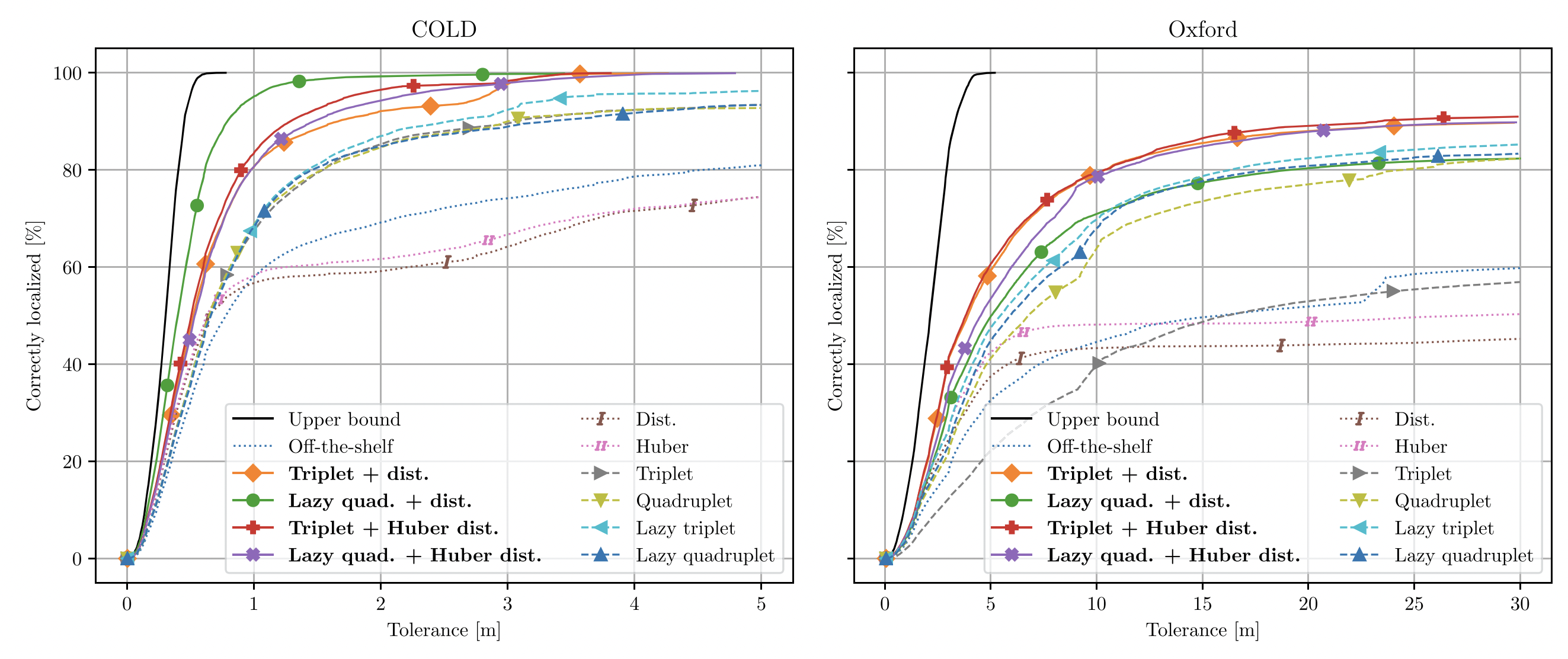
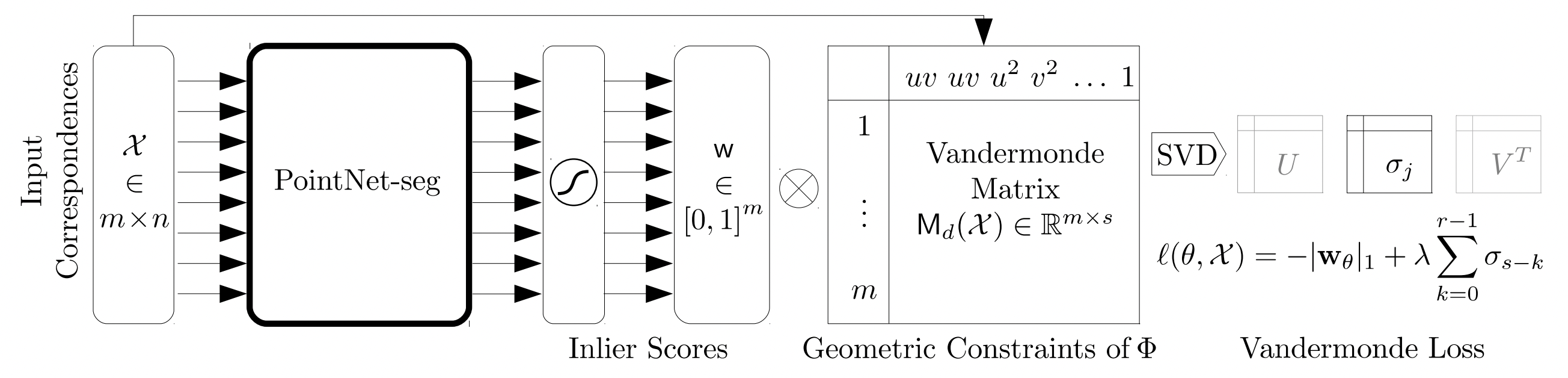
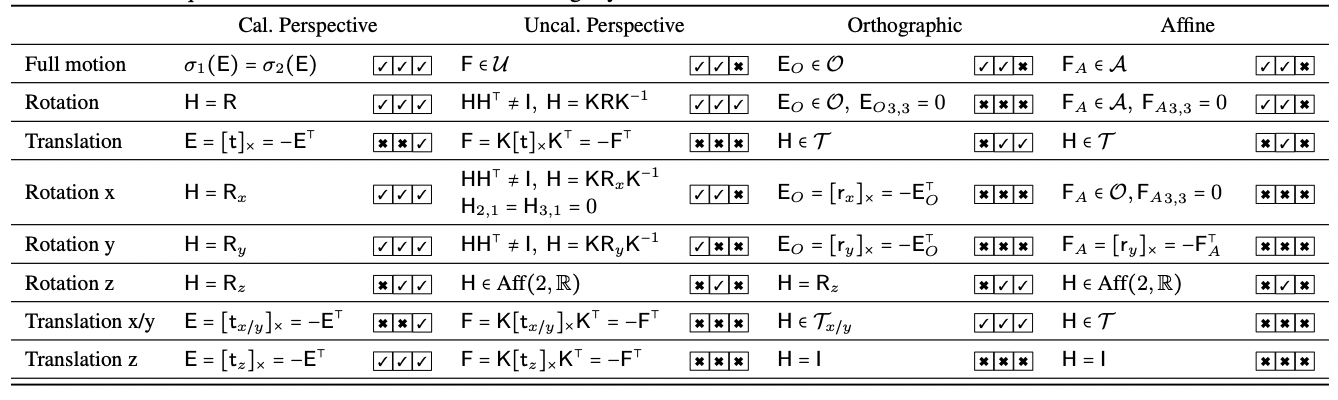
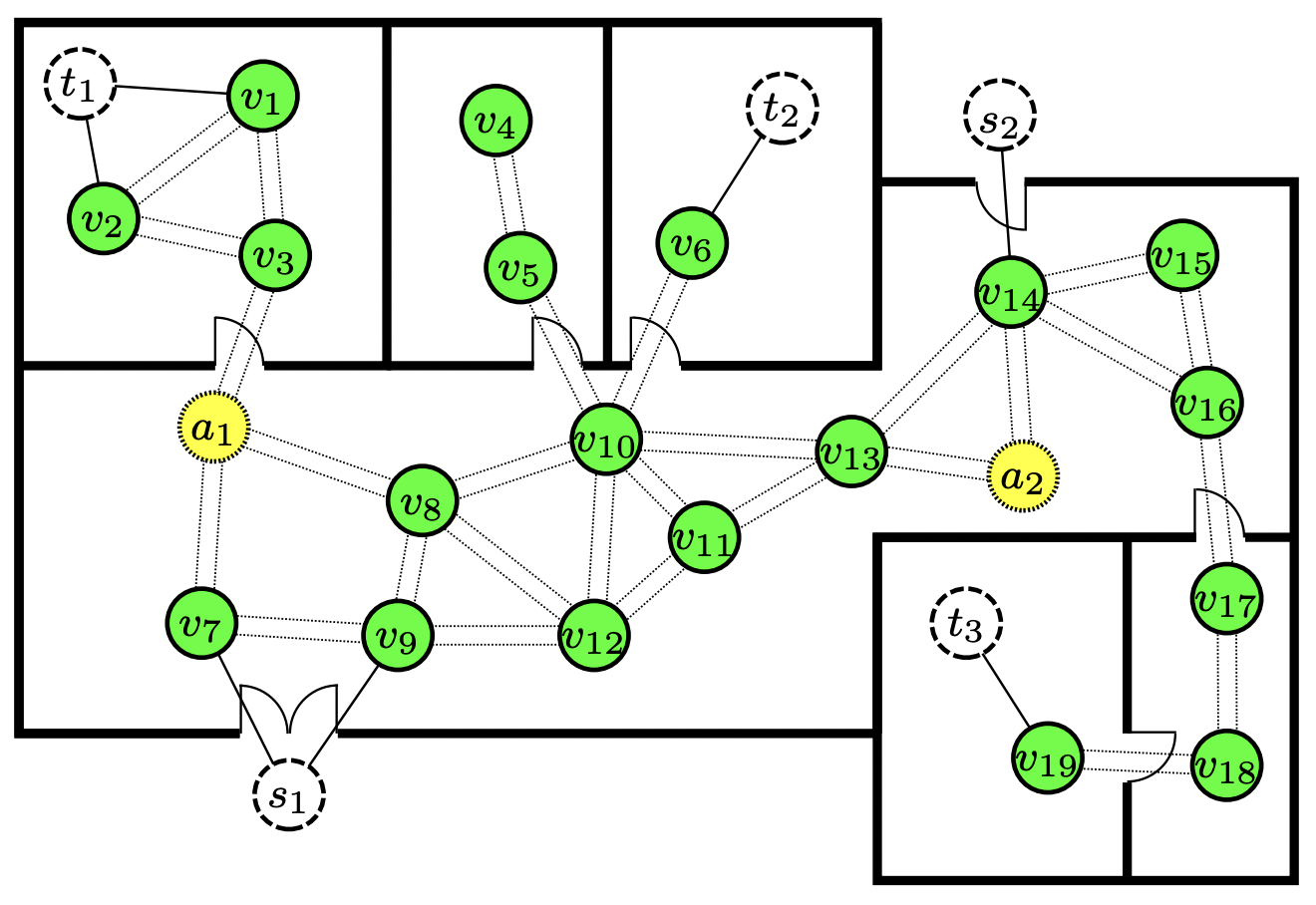
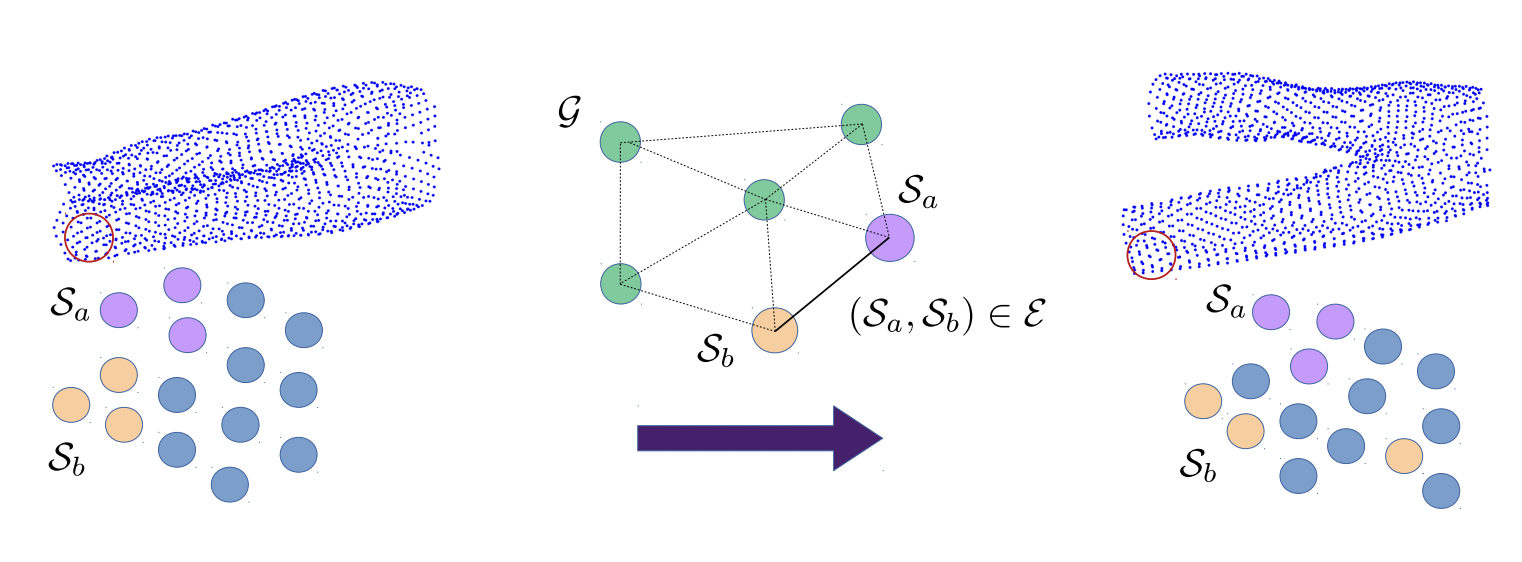
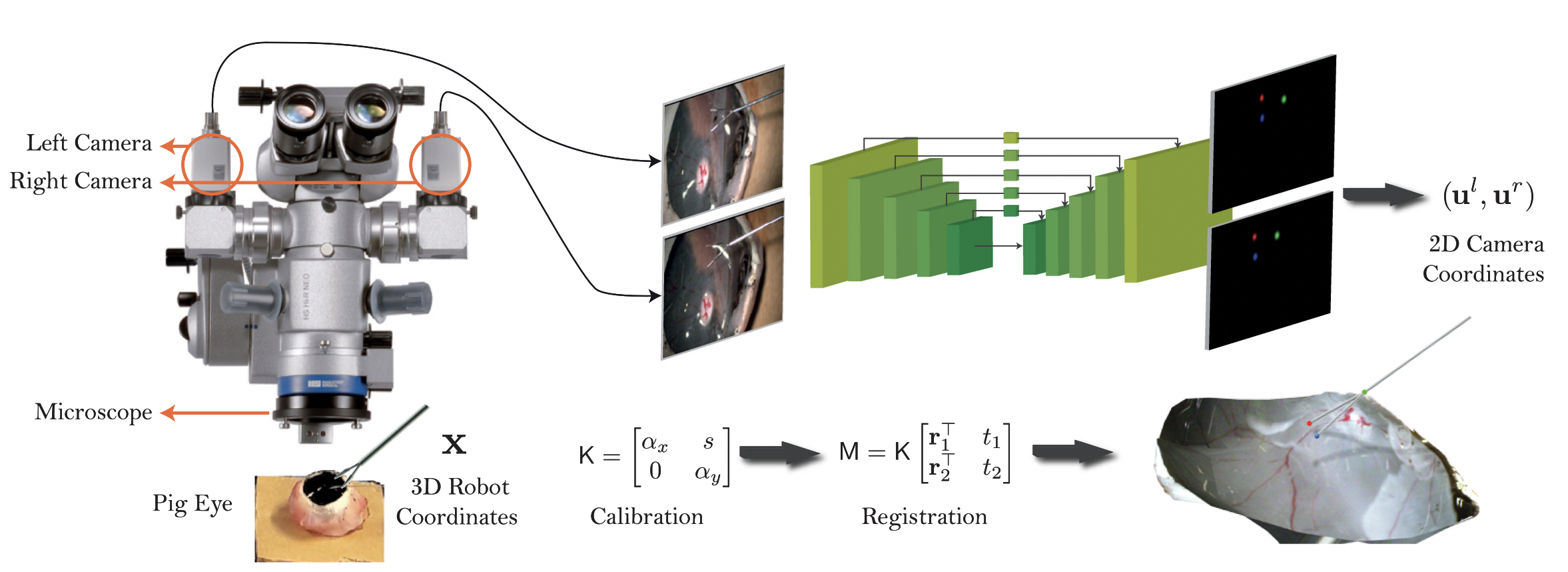
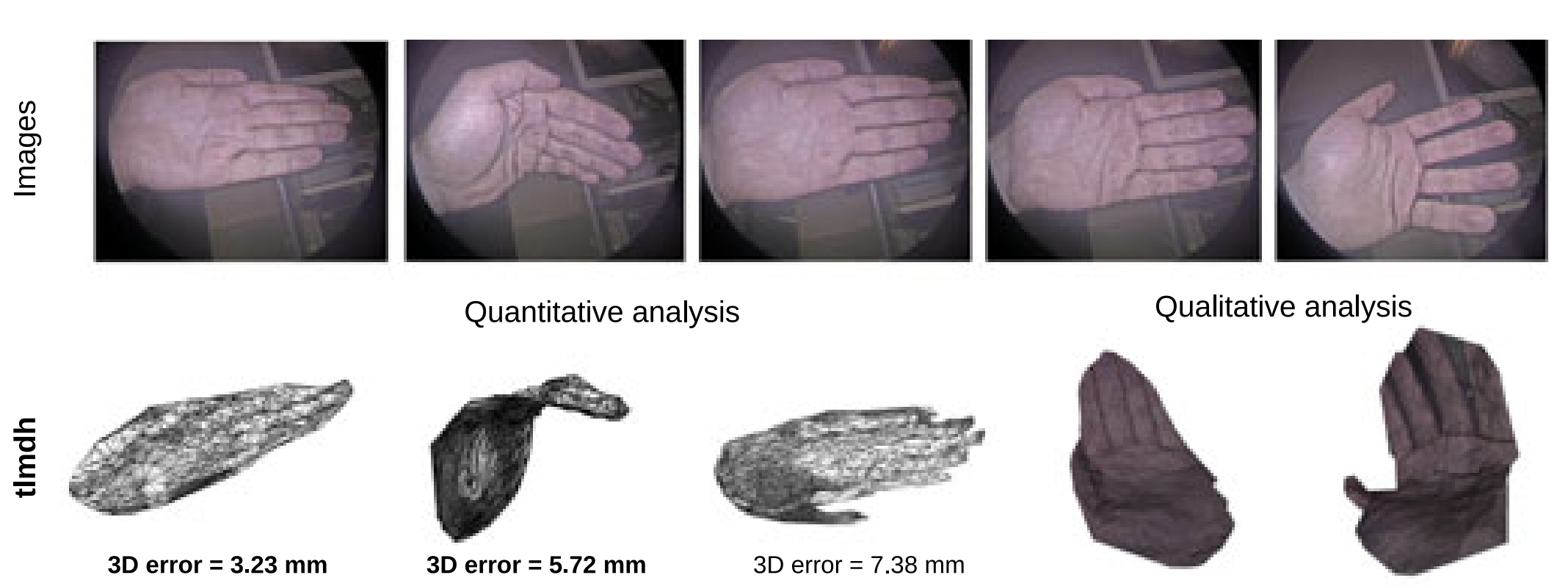
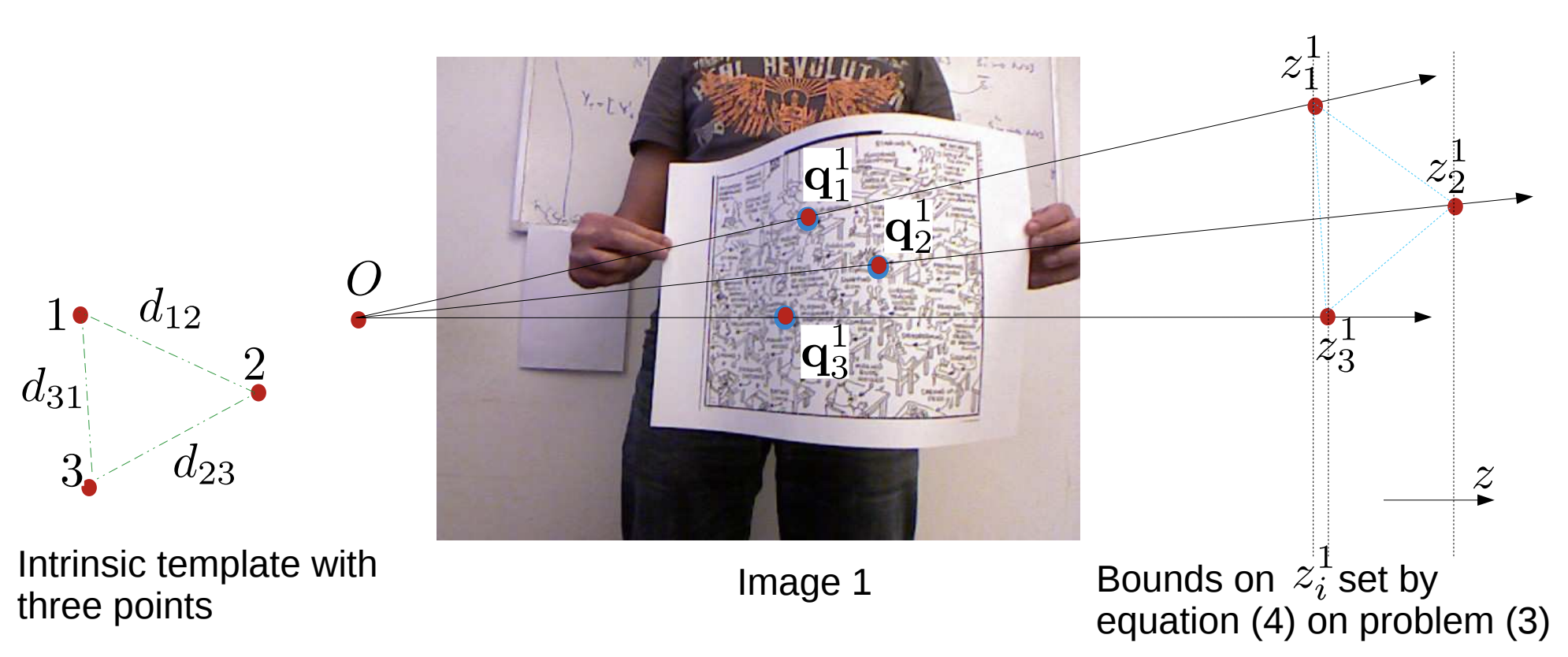
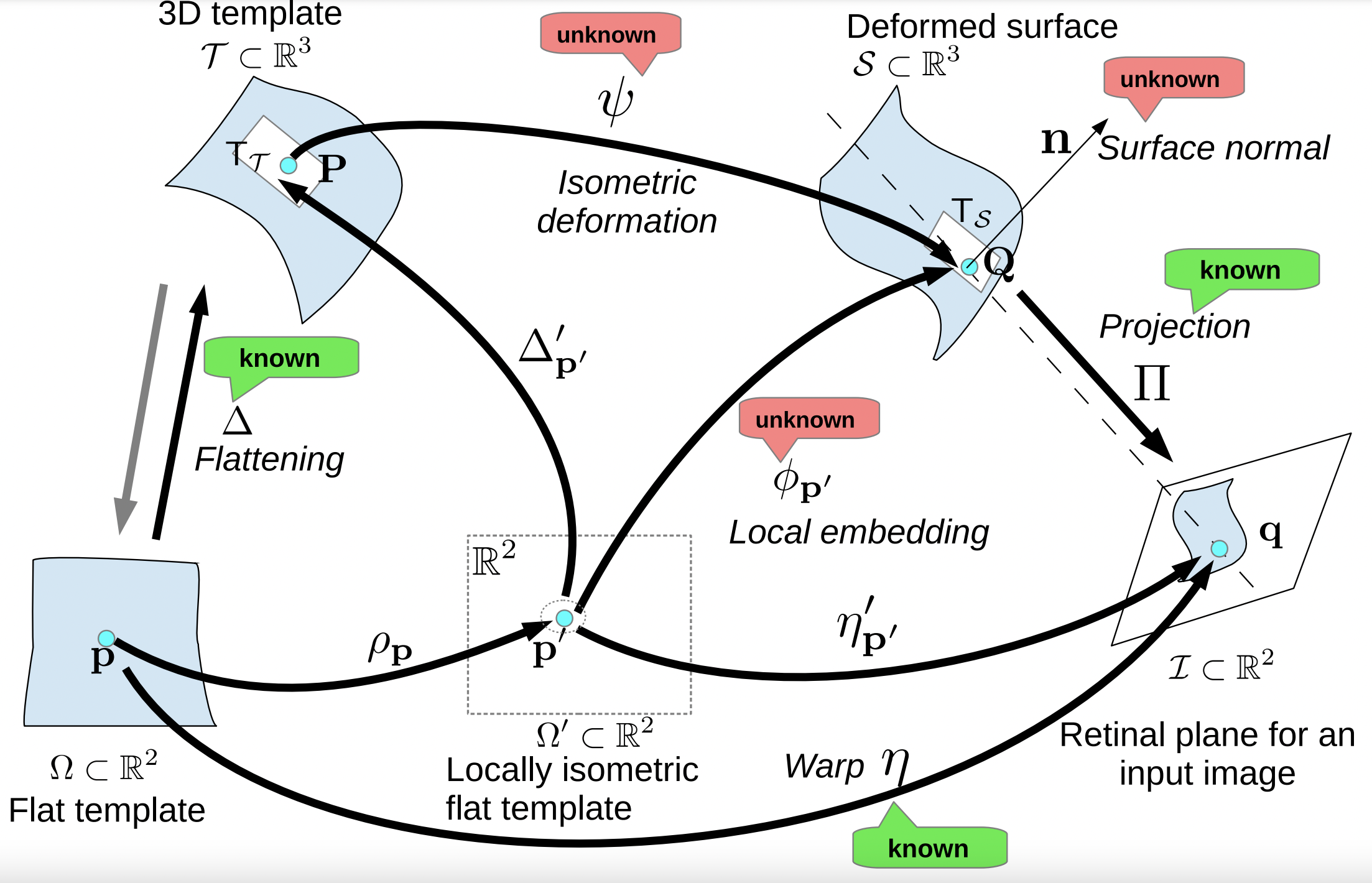
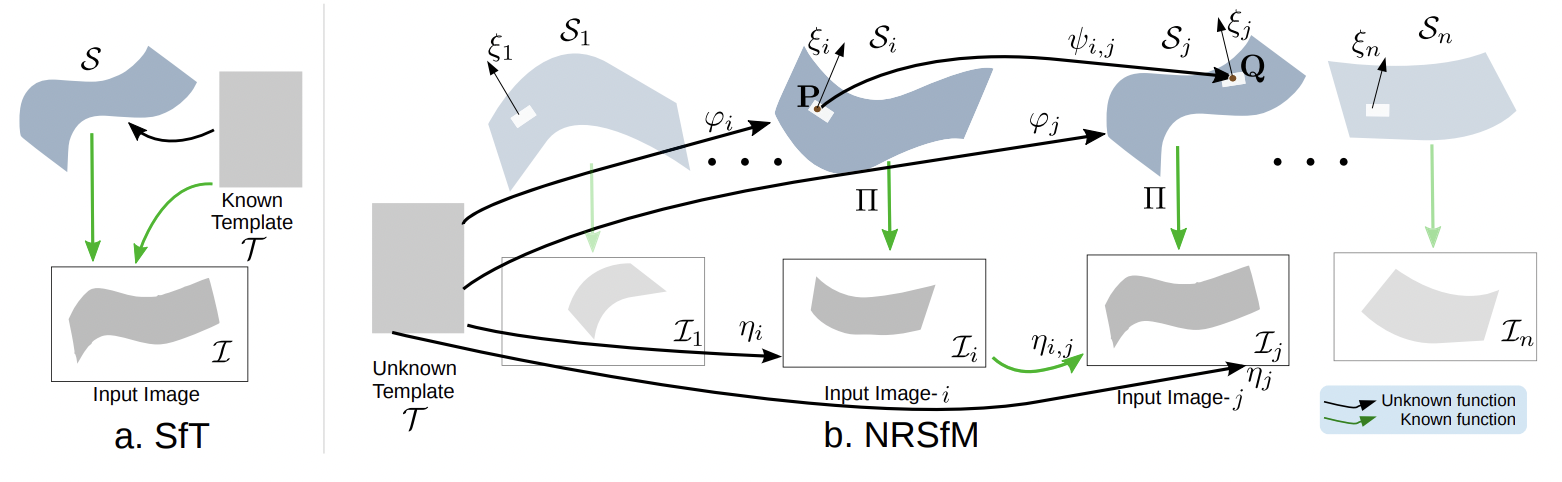
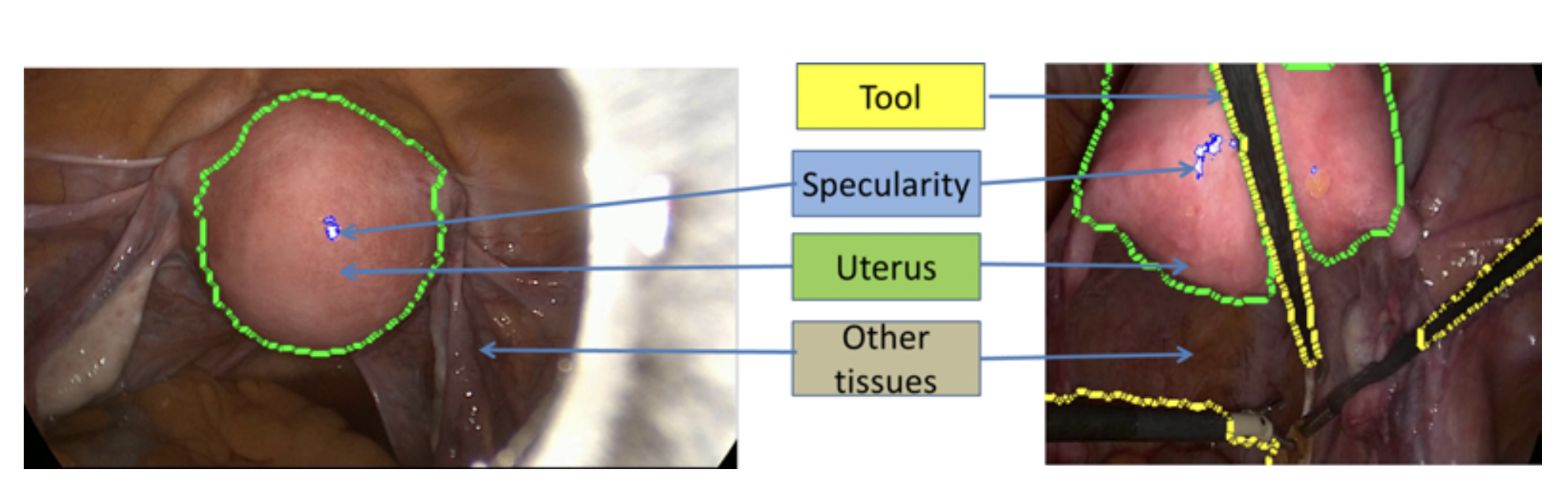
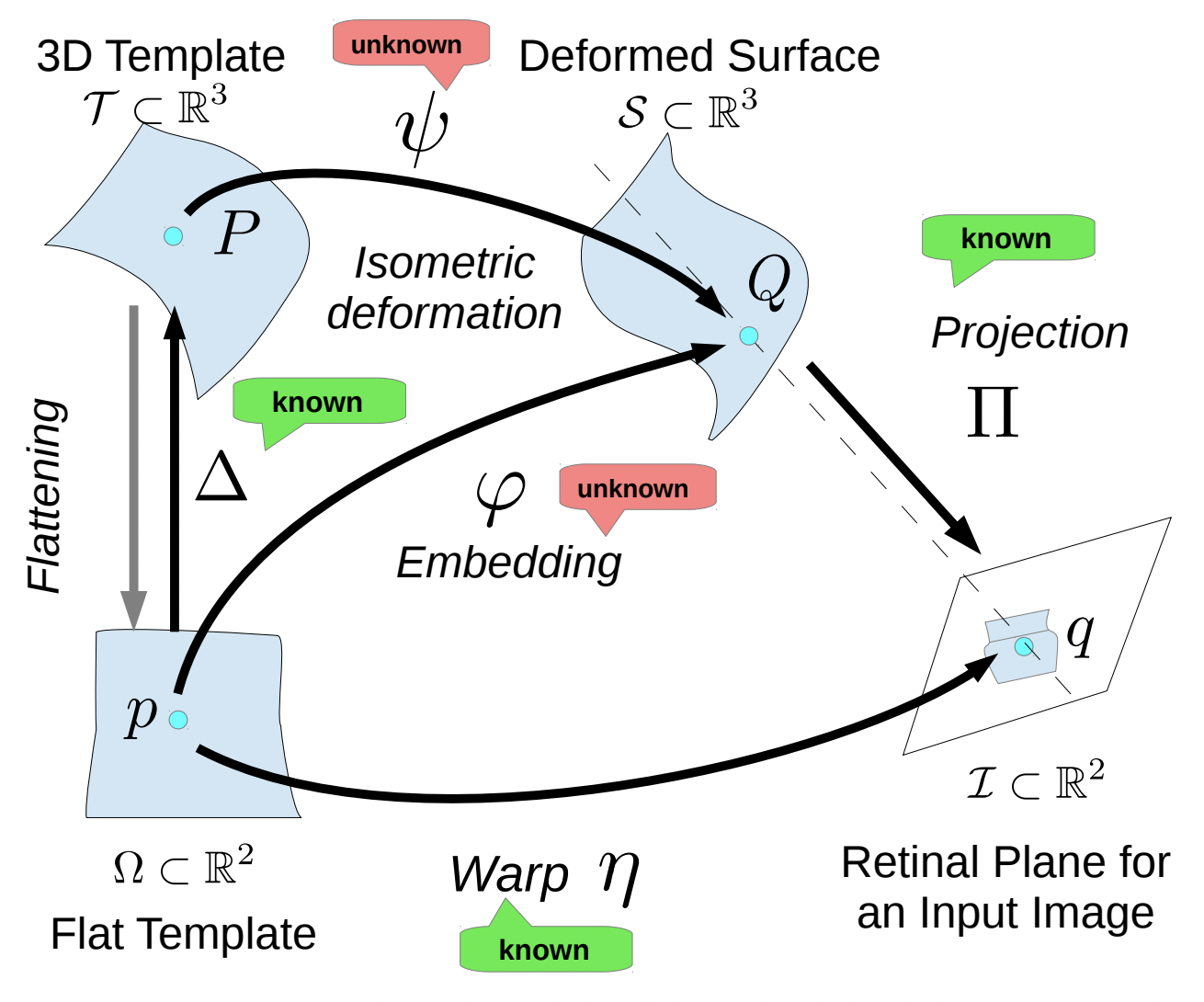
We propose COM4D (Compositional 4D), a method that consistently and jointly predicts the structure and spatio-temporal configuration of 4D/3D objects using only static multi-object or dynamic single object supervision.